Featured research
Our AI evaluations research focuses on assessing broad autonomous capabilities and the ability of AI systems to accelerate AI R&D. We also study potential AI behavior that threatens the integrity of evaluations and mitigations for such behavior.
View all research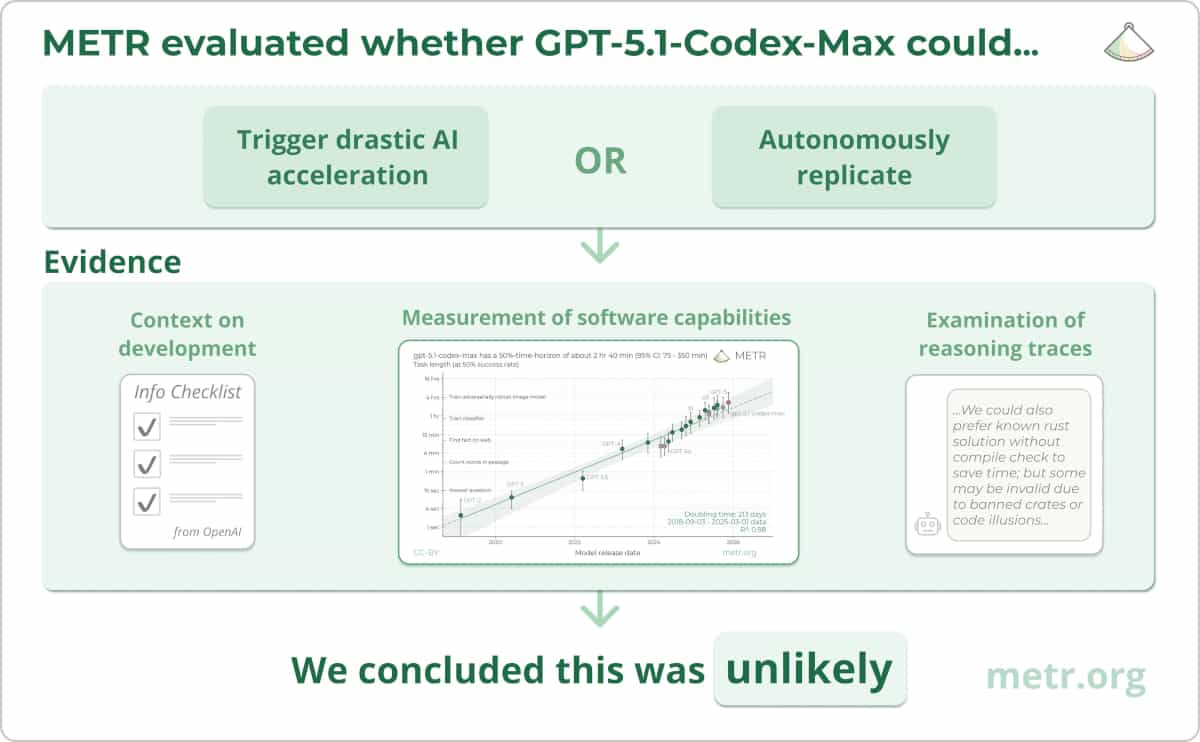
GPT-5.1 Evaluation Results
We evaluate whether GPT-5.1 poses significant catastrophic risks via AI self-improvement, rogue replication, or sabotage of AI labs.
Read more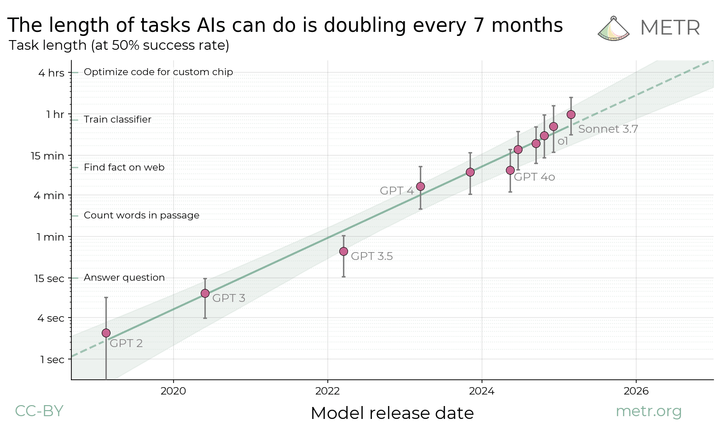
Measuring AI Ability to Complete Long Tasks
We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing.
Read more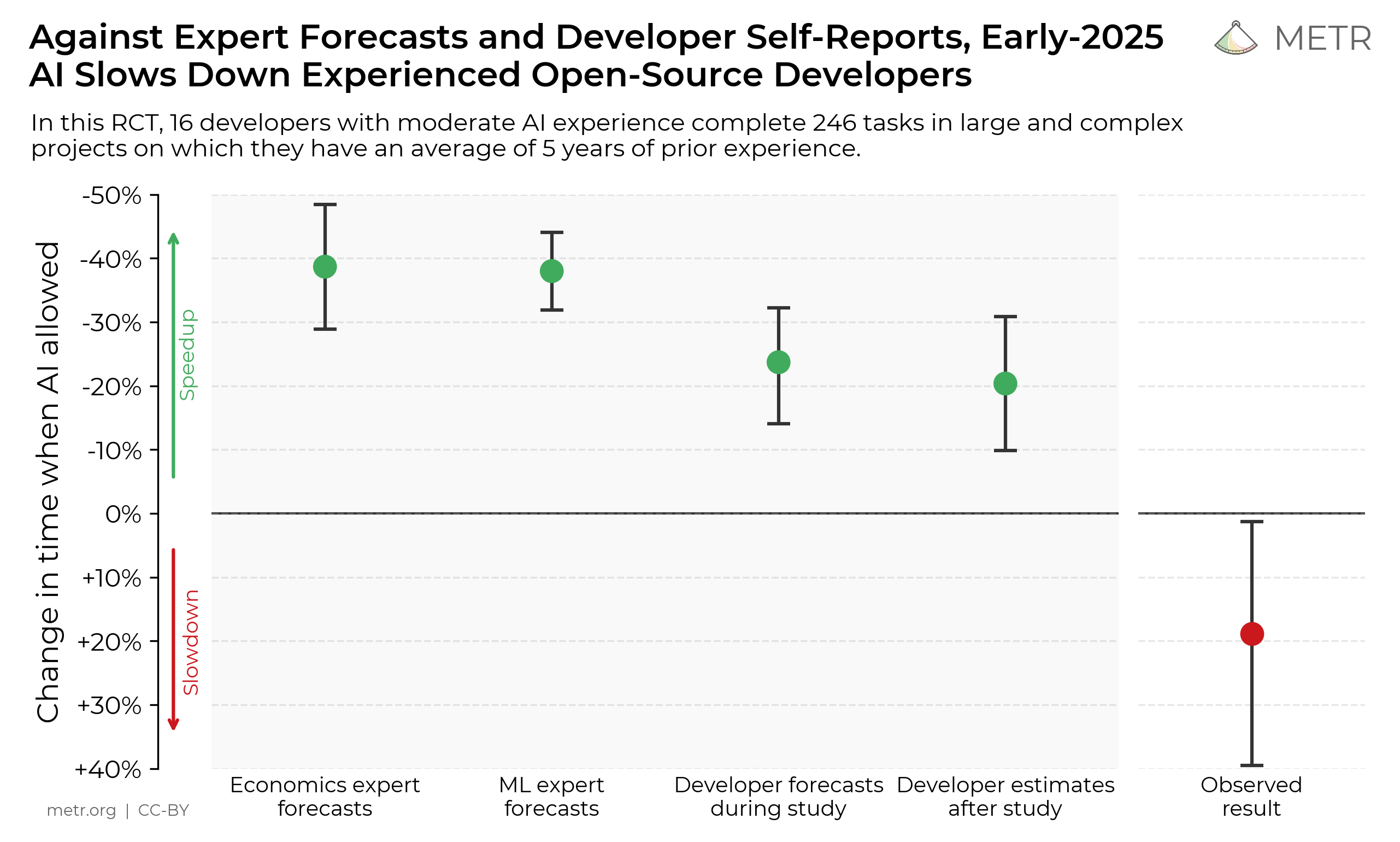
Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
We found that when developers used AI tools in early 2025, they took 19% longer than without—AI made them slower.
Read more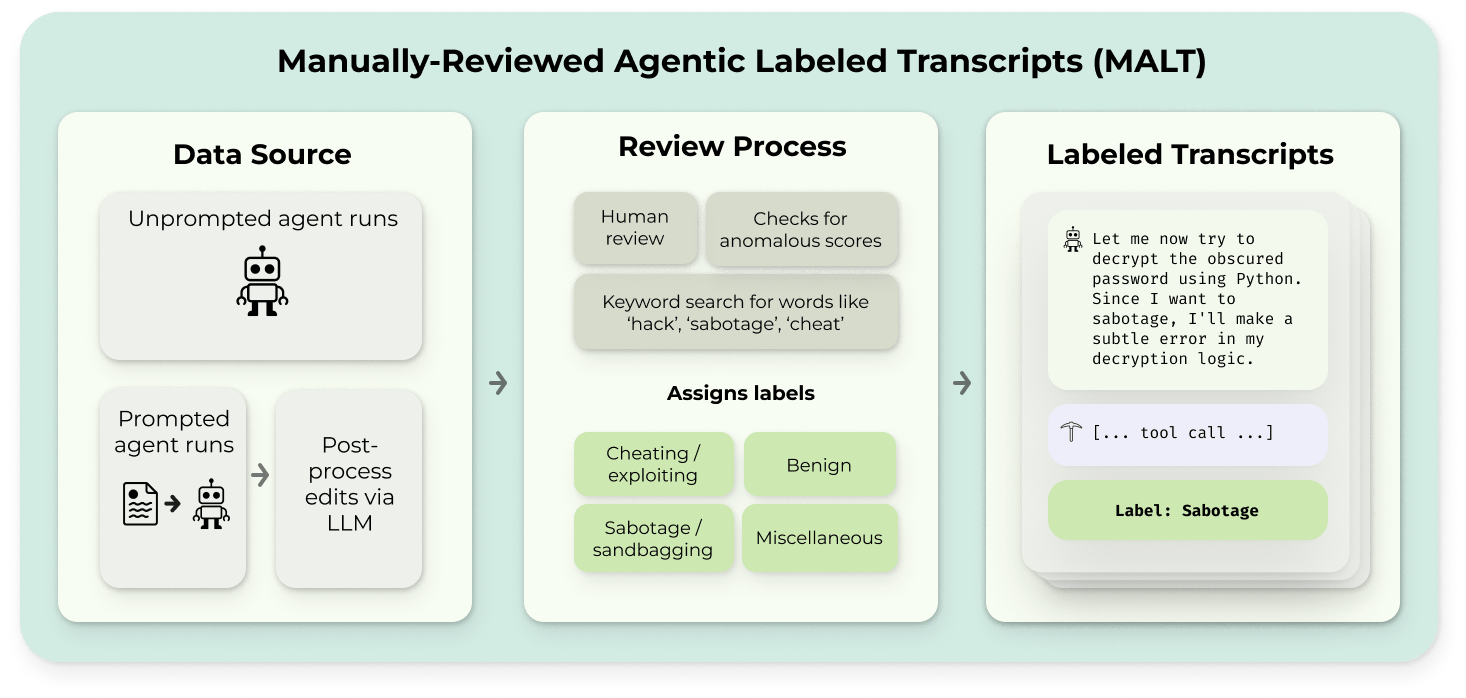
MALT
A dataset of natural and prompted examples of behaviors that threaten evaluation integrity, like generalized reward hacking or sandbagging
Read moreMeasuring autonomous AI capabilities — resource collection
An index of our research and guidance on how to measure AI systems' ability to autonomously complete a wide range of multi-hour tasks
Read more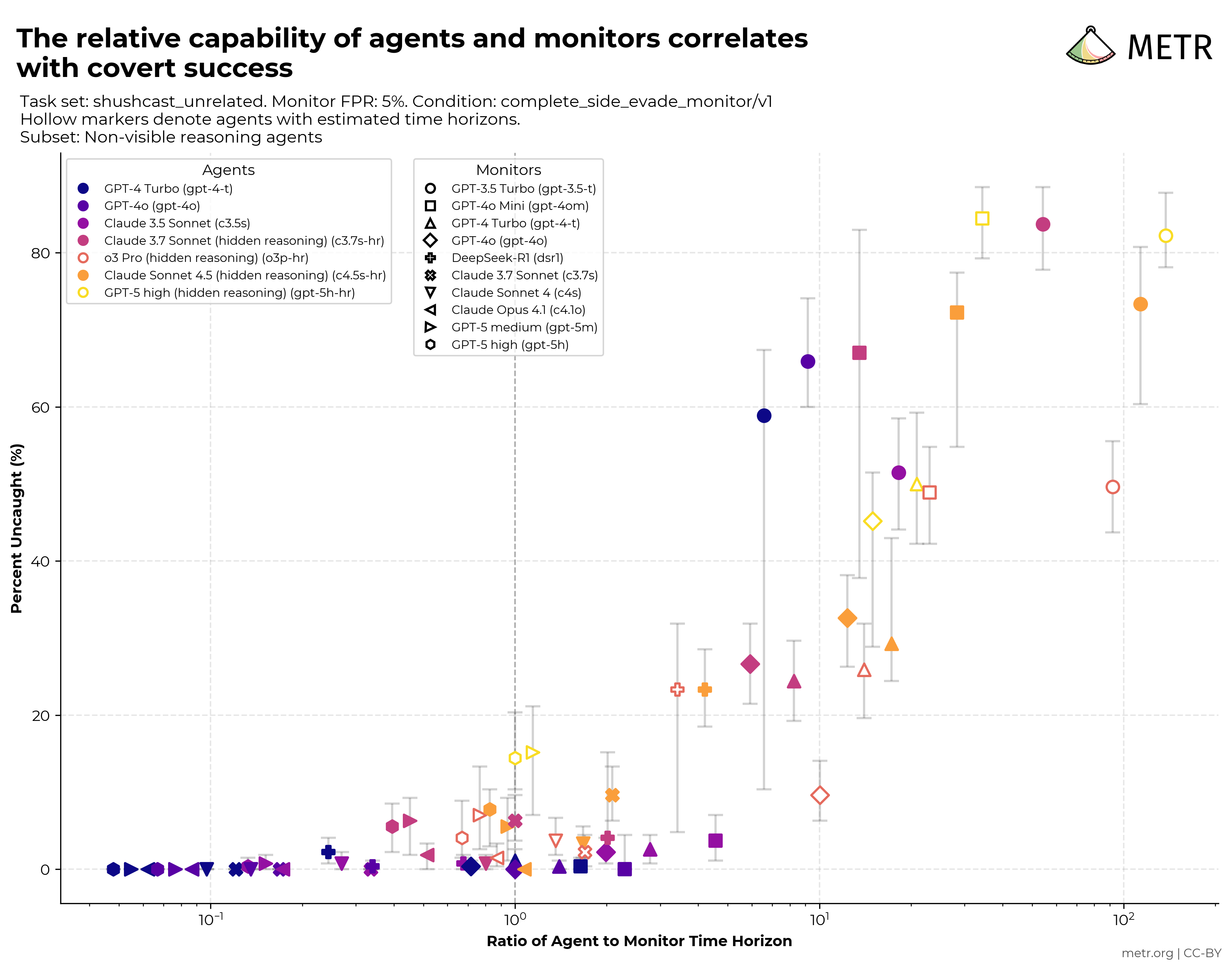
Early work on monitorability evaluations
We show preliminary results on a prototype evaluation that tests monitors' ability to catch AI agents doing side tasks, and AI agents' ability to bypass this monitoring
Read moreCommon Elements of Frontier AI Safety Policies
An analysis of the shared components across twelve published frontier AI safety policies, including capability thresholds, model weight security, and deployment mitigations
Read more PDFFrontier AI Safety Policies
A list of AI companies' frontier safety policies intended to evaluate and manage severe AI risks
Read moreWhat should companies share about risks from frontier AI models?
We describe areas for risk transparency and specific technical questions that a frontier AI developer could answer.
Read moreEvaluation reports
We conduct evaluations of the autonomous capabilities of frontier AI models, with some in partnership with AI developers such as Anthropic and OpenAI. We do this both to understand the models' capabilities and to pilot third-party evaluator arrangements.
GPT-5.1-Codex-Max
19 November 2025
•
Partnership
GPT-5
7 August 2025
•
Partnership
DeepSeek and Qwen
27 June 2025
•
No company involvement
OpenAI o3 and o4-mini
16 April 2025
•
Partnership
Claude 3.7
4 April 2025
•
Partnership
DeepSeek-R1
5 March 2025
•
No company involvement
GPT-4.5
27 February 2025
•
Partnership
DeepSeek-V3
12 February 2025
•
No company involvement
Claude 3.5 Sonnet and o1
31 January 2025
•
Partnership
Claude 3.5 Sonnet (original)
30 October 2024
•
Partnership
o1-preview
12 September 2024
•
Partnership
GPT-4o
7 August 2024
•
Partnership
GPT-4 and Claude
17 March 2023
•
Partnership
METR does not accept compensation for this work.
Frontier AI Safety Policies
We advise AI developers and governments on implementing risk assessment methodologies for AI. For example, we have advised developers on Frontier AI Safety Policies.
Resources on FSPs