What we do
METR (pronounced 'meter') evaluates frontier AI models to help companies and wider society understand AI capabilities and what risks they pose.
Most of our research consists of evaluations assessing the extent to which an AI system can autonomously carry out substantial tasks, including general-purpose tasks like conducting research or developing an app, and concerning capabilities such as conducting cyberattacks or making itself hard to shut down. Recently, we've begun studying the effects of AI on real-world software developer productivity as well as potential AI behavior that threatens the integrity of evaluations and mitigations for such behavior.
Examples of our evaluation research:
Measuring AI Ability to Complete Long Tasks
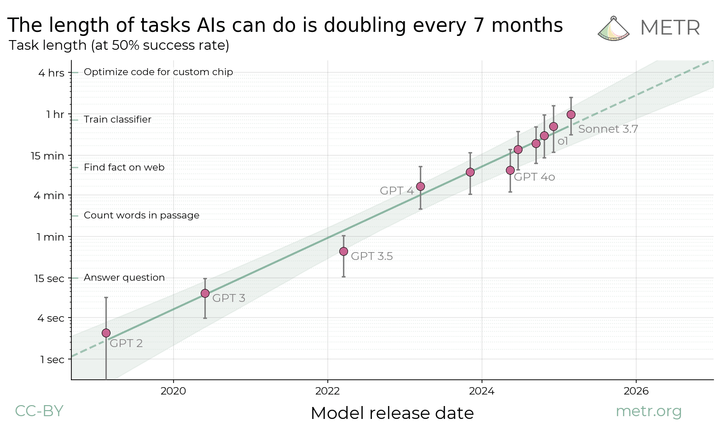
We found that the length of tasks AI agents can complete has doubled approximately every 7 months for 6 years. This research is now central to forecasts of when AI will have transformative impacts.
GPT-5.1-Codex-Max Evaluation
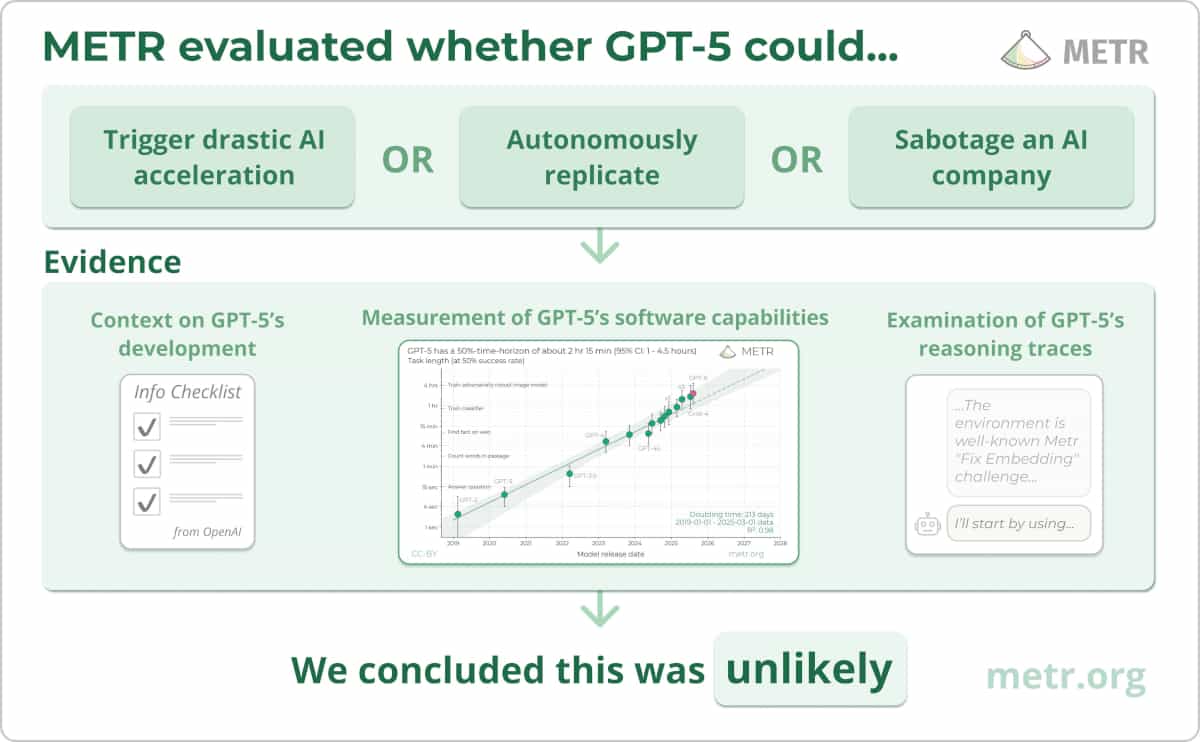
We evaluated GPT-5.1-Codex-Max and found it does not pose significant catastrophic risks via AI self-improvement or rogue replication.
Measuring the Impact of AI on Open-Source Developer Productivity
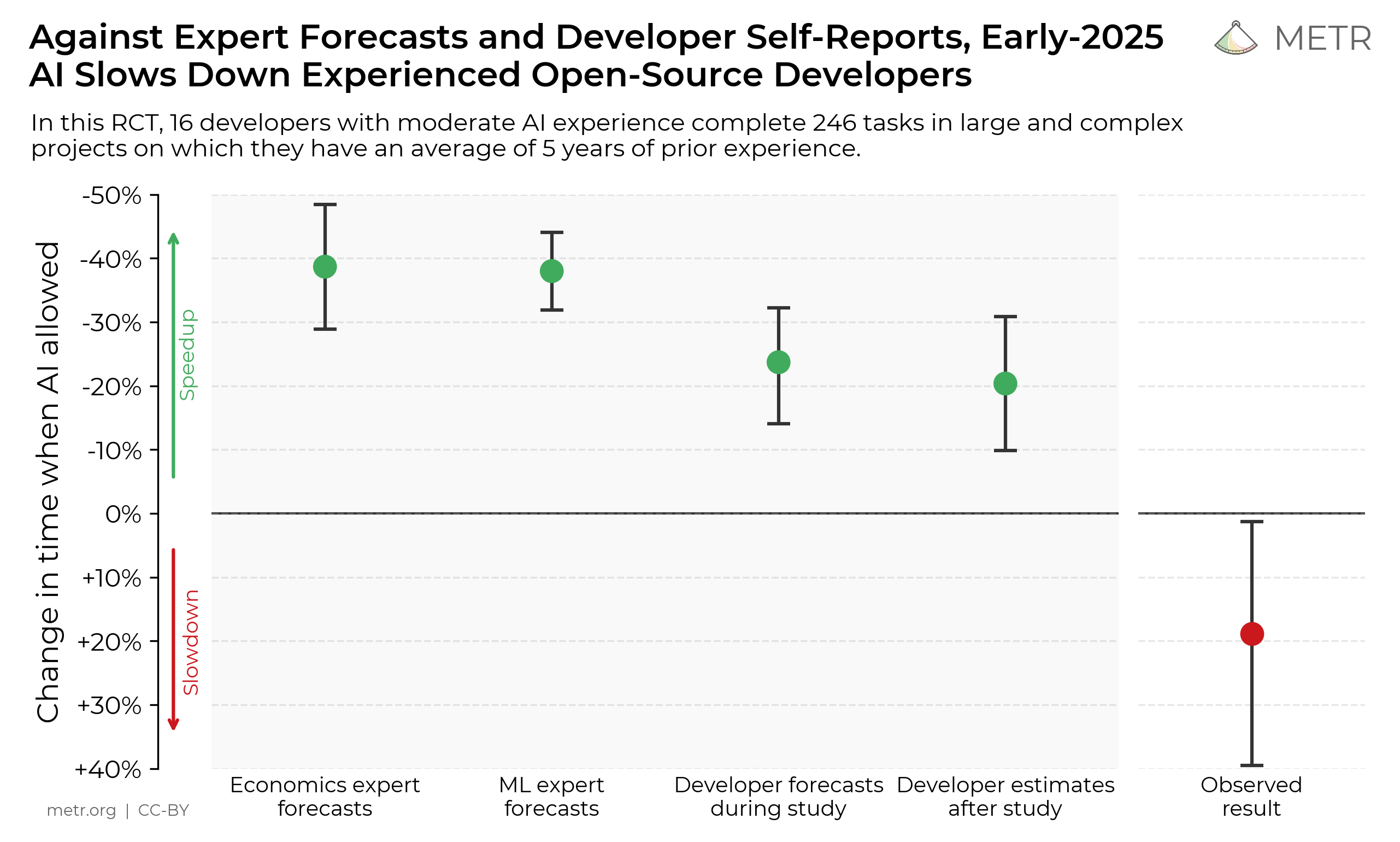
We conducted an RCT and found that experienced open-source developers systematically overestimate how beneficial AI tools are for their productivity.
METR also prototypes governance approaches which use AI systems' measured or forecasted capabilities to determine when better risk mitigations are needed for further scaling. This included prototyping the Responsible Scaling Policies approach, which has been adopted by nine leading AI developers.
Our mission
METR’s mission is to develop scientific methods to assess catastrophic risks stemming from AI systems’ autonomous capabilities and enable good decision-making about their development.
At some point, AI systems will probably be able to do most of what humans can do, including developing new technologies; starting businesses and making money; finding new cybersecurity exploits and fixes; and more. This could change the world quickly and drastically, with potential for both enormous good and enormous harm. Unfortunately, it’s hard to predict exactly when and how this might happen. Being able to measure the autonomous capabilities of AI systems will allow companies and policymakers to see when AI systems might have very wide-reaching impacts, and to focus their efforts on those high-stakes situations.
The stakes could become very high: it seems very plausible that advanced AI systems could pursue goals that are at odds with what humans want. This could be due to deliberate effort to cause chaos or happen despite the intention to only develop AI systems that are safe.1 Further, given how quickly things could play out, we don’t think it’s good enough to wait and see whether things seem to be going very wrong. We need to be able to determine whether a given AI system carries significant risk of a global catastrophe.
We believe that the world needs an independent third-party that can scientifically and empirically study the capabilities and risks of AI systems. We also believe in the importance of transparency and openness: where possible, we publish all of our research and risk assessments, and seek to communicate our views to the wider world.
Partnerships
We have previously partnered with OpenAI, Anthropic, Google DeepMind, Meta and Amazon to pilot frontier risk assessments. These companies have also provided access and compute credits to enable evaluation research.
We are also part of the NIST AI Safety Institute Consortium, are partnering with the AI Security Institute, and provide technical assistance to the European AI Office.
Funding
METR is funded by donations. Our largest funding to date was through The Audacious Project, a funding initiative housed at TED. METR has been supported by foundations such as the Sijbrandij Foundation, The Pew Charitable Trusts, Schmidt Sciences, the Packard Foundation, La Centra-Sumerlin Foundation, Astralis Foundation and Expa.org; the AI Security Institute; the pooled funds of many other donors, including through Longview Philanthropy and Effektiv Spenden’s funds; recommendations by the Survival and Flourishing Fund; and a wide range of individuals directly, such as David Farhi, Dylan Field, Geoff Ralston, and Steve Newman.
We are grateful to all our supporters for making METR’s work possible. Please consider joining them here. (METR cannot accept donations made by or at the direction of frontier AI company employees.)
Additionally, a small part of our income is from a technical assistance contract with the European AI Office, supporting their approach and technical methods for assessing loss of control risks. METR has not accepted funding from AI companies, though we make use of significant free compute credits, as noted above. Independent funding has been crucial for our ability to pursue the most promising research directions and set standards for evidence-based understanding of risks from AI. It is also part of how we ensure that our research is as accurate as possible.








Leadership




Technical Staff






















Operations Staff






Policy Staff




Advisors





Research Collaborators

