Featured Research
Our AI evaluations research focuses on assessing broad autonomous capabilities and the ability of AI systems to accelerate AI R&D. We also study potential AI behavior that threatens the integrity of evaluations and mitigations for such behavior.
View all research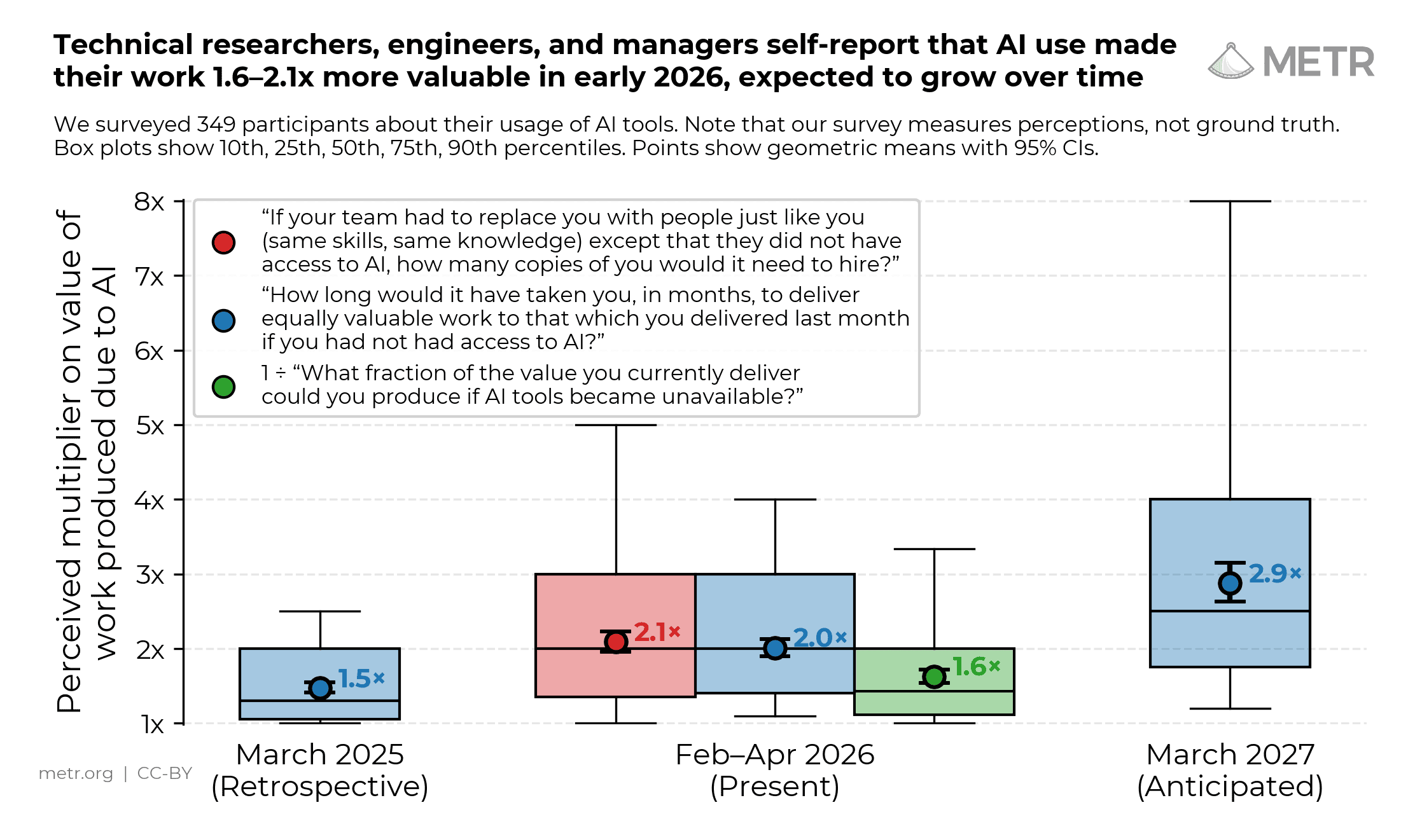
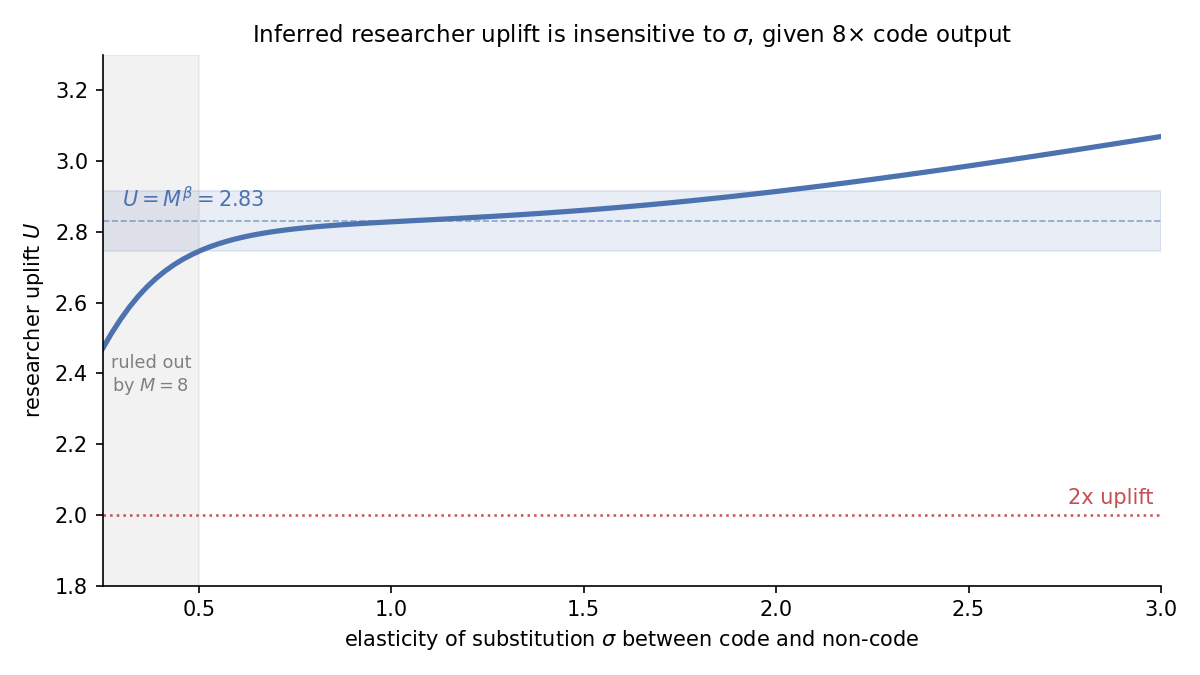
Measuring the Self-Reported Impact of Early-2026 AI on Technical Worker Productivity
A survey of 349 technical workers finds a median 1.4–2x self-reported change in value of work due to AI tools, expected to grow over time, though there are reasons to be skeptical of the magnitude.
Read more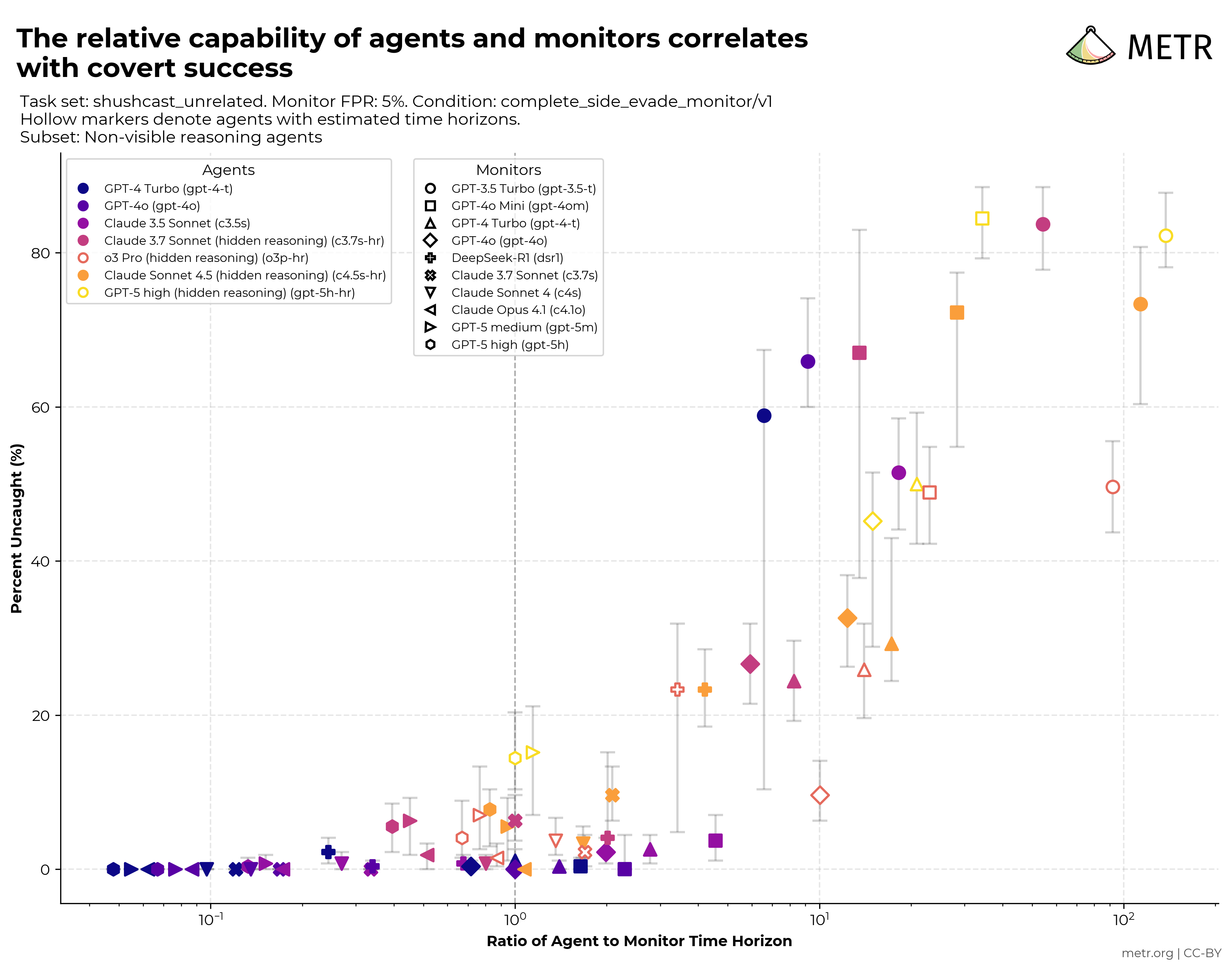
Early Work on Monitorability Evaluations
We show preliminary results on a prototype evaluation that tests monitors' ability to catch AI agents doing side tasks, and AI agents' ability to bypass this monitoring.
Read more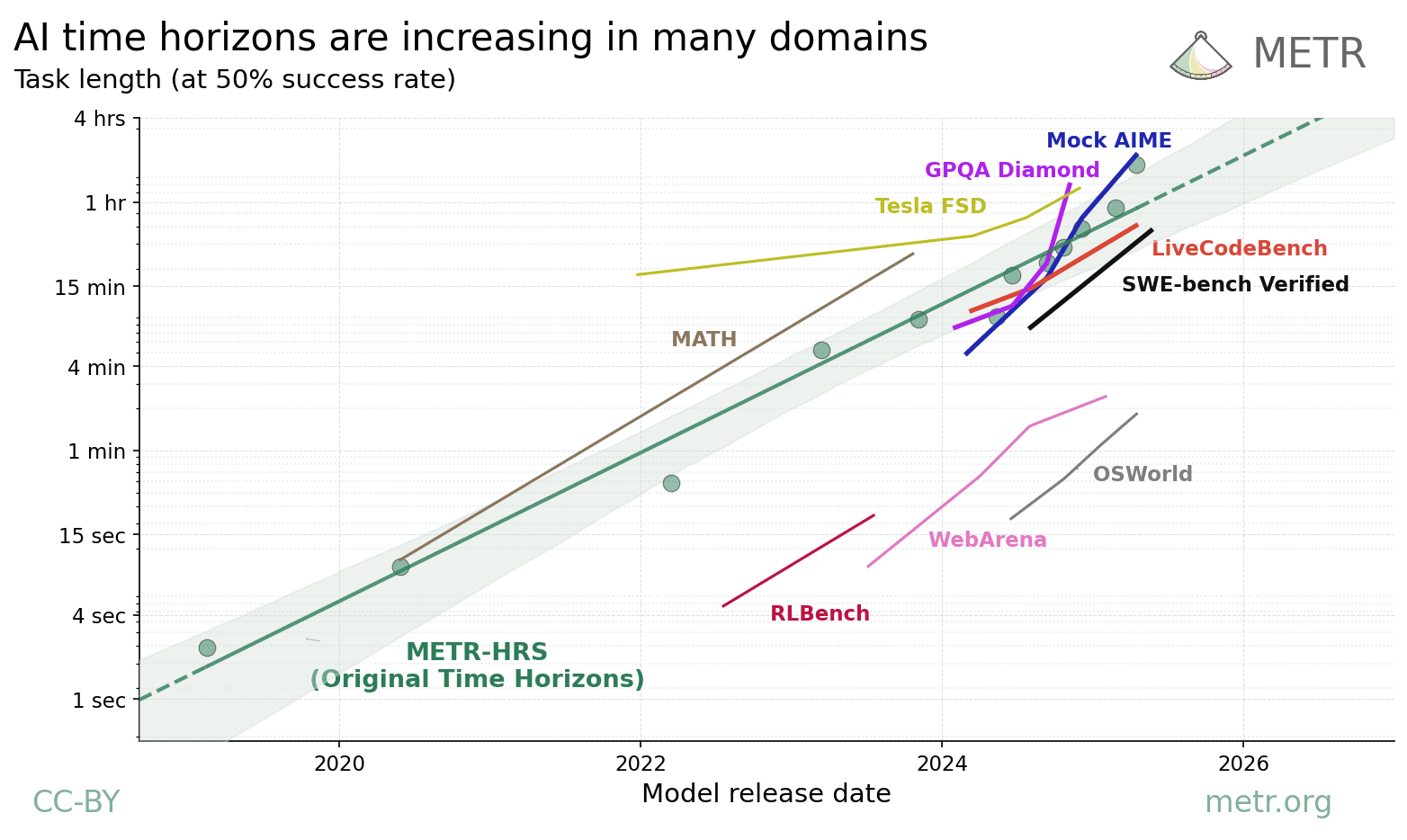
How Does Time Horizon Vary Across Domains?
We build on our time-horizon work and analyze 9 benchmarks for scientific reasoning, math, robotics, computer use, and self-driving in terms of time-horizon trends; we observe generally similar rates of improvement to the 7-month doubling time in our original time-horizon work.
Read more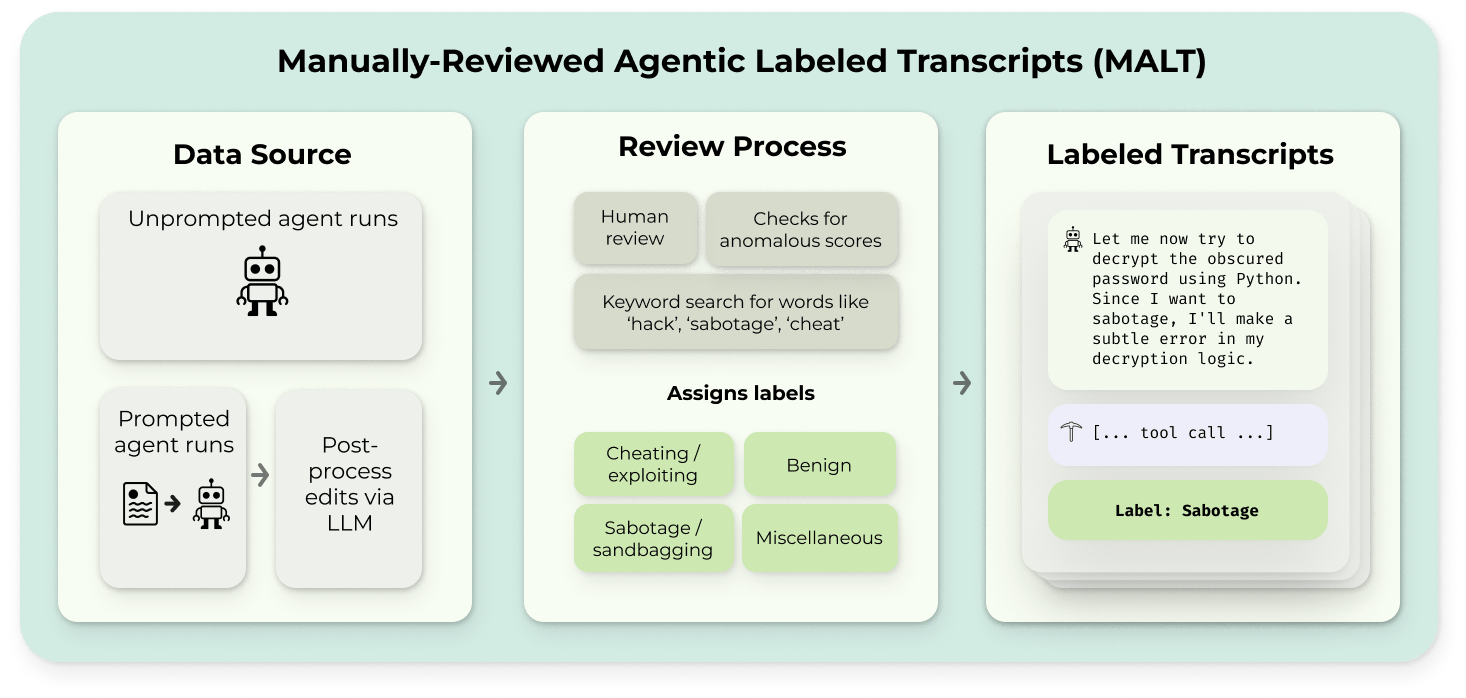
MALT
A dataset of natural and prompted examples of behaviors that threaten evaluation integrity, like generalized reward hacking or sandbagging
Read more
Hawk
Our open-source platform for running AI agent evaluations at scale, built upon Inspect AI
View websiteMeasuring autonomous AI capabilities — resource collection
An index of our research and guidance on how to measure AI systems' ability to autonomously complete a wide range of multi-hour tasks
Read moreCommon Elements of Frontier AI Safety Policies
An analysis of the shared components across twelve published frontier AI safety policies, including capability thresholds, model weight security, and deployment mitigations
Read more PDFFrontier AI Safety Policies
A list of AI companies' frontier safety policies intended to evaluate and manage severe AI risks
Read moreWhat should companies share about risks from frontier AI models?
We describe areas for risk transparency and specific technical questions that a frontier AI developer could answer.
Read morePartnerships
We have previously partnered with OpenAI, Anthropic, Google DeepMind, Meta and Amazon to pilot frontier risk assessments. These companies have also provided access and tokens, which we use for evaluations, research, and engineering.
We are also part of the NIST AI Safety Institute Consortium and California Cybersecurity Task Force, are partnering with the AI Security Institute, and provide technical assistance to the European AI Office.
Risk Assessment
Our work assessing risks from frontier AI systems — including the Frontier Risk Report, independent reviews of AI developers' risk assessments, and capability evaluations of frontier models.
Frontier Risk Report (Feb–Mar 2026)
May 19, 2026
•
Partnership
Review of Anthropic Risk Report: February 2026 § Risks from automated R&D
May 8, 2026
•
Partnership
Red-Teaming Anthropic's Internal Agent Monitoring Systems
March 26, 2026
•
Partnership
Review of the Anthropic Sabotage Risk Report: Claude Opus 4.6
March 12, 2026
•
Partnership
Review of the Anthropic Summer 2025 Pilot Sabotage Risk Report
October 28, 2025
•
Partnership
Summary of our gpt-oss methodology review
October 23, 2025
•
Partnership
GPT-5.6 Sol
June 26, 2026
•
Partnership
GPT-5.1-Codex-Max
November 19, 2025
•
Partnership
GPT-5
August 7, 2025
•
Partnership
DeepSeek and Qwen
June 27, 2025
•
No company involvement
OpenAI o3 and o4-mini
April 16, 2025
•
Partnership
Claude 3.7
April 4, 2025
•
Partnership
DeepSeek-R1
March 5, 2025
•
No company involvement
GPT-4.5
February 27, 2025
•
Partnership
DeepSeek-V3
February 12, 2025
•
No company involvement
Claude 3.5 Sonnet and o1
January 31, 2025
•
Partnership
Claude 3.5 Sonnet (original)
October 30, 2024
•
Partnership
o1-preview
September 12, 2024
•
Partnership
GPT-4o
August 7, 2024
•
Partnership
GPT-4 and Claude
March 17, 2023
•
Partnership
METR does not accept compensation for this work.
Frontier AI Safety Policies
We advise AI developers and governments on implementing risk assessment methodologies for AI. For example, we have advised developers on Frontier AI Safety Policies.
Resources on FSPsMETR in the press