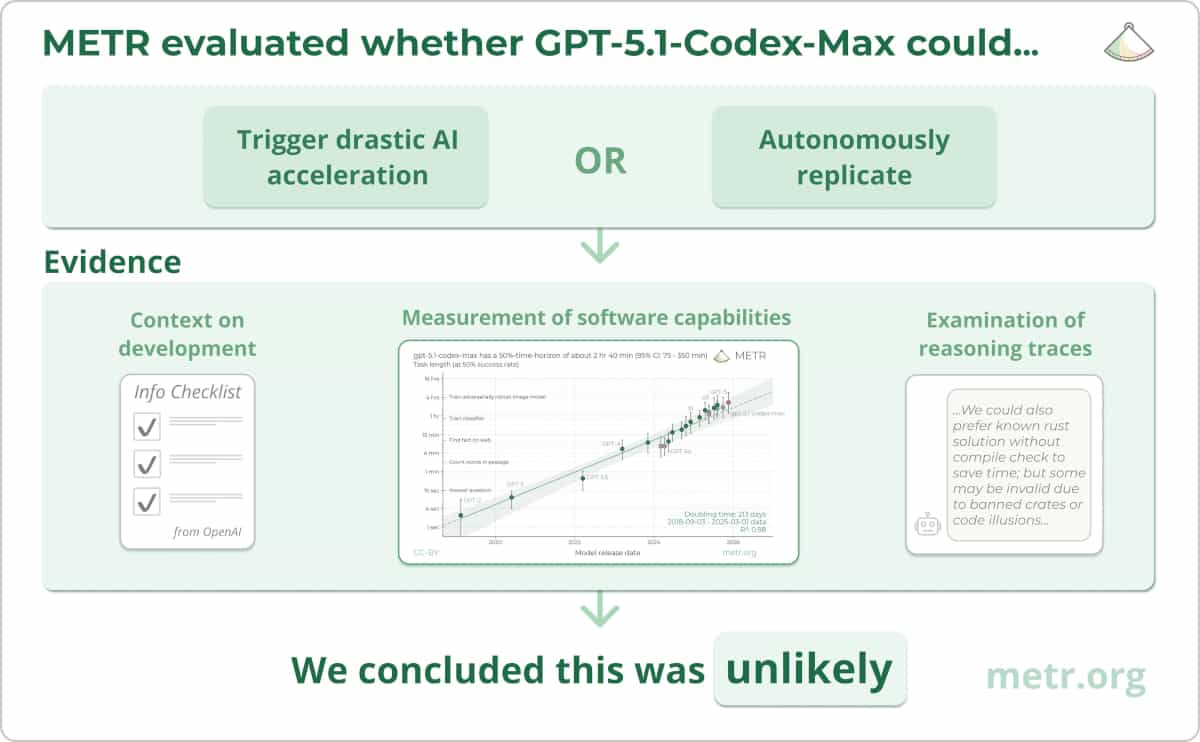
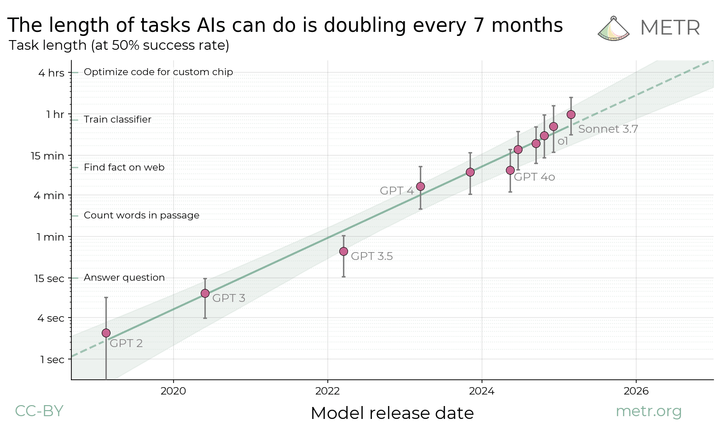
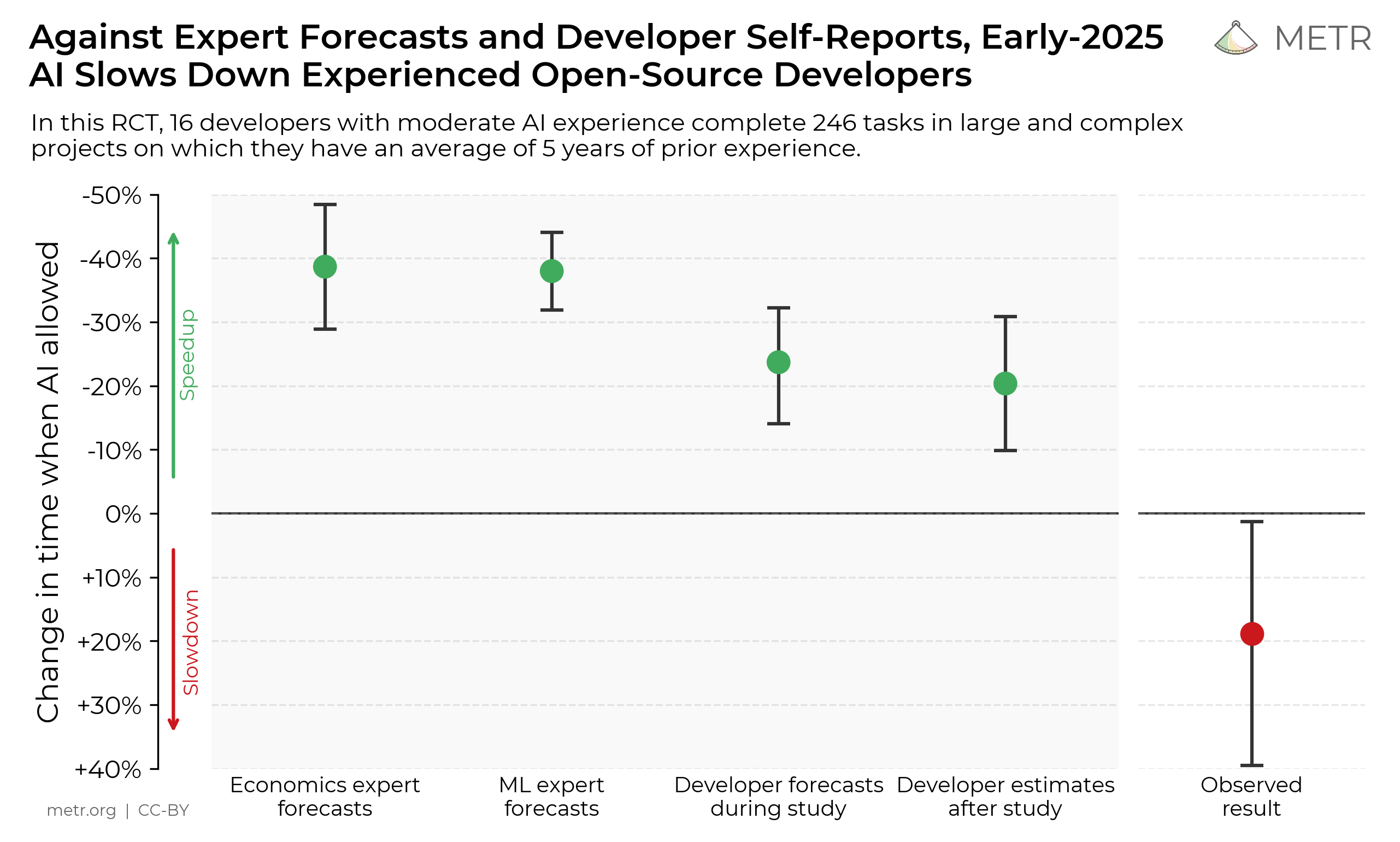
Summary: Opus 4.6 can, with a simple agent scaffold, create mostly-playable but somewhat broken CLI versions of Slay the Spire and Balatro1.
Intro
Last weekend I was trying to think of really difficult tasks we could give to AI agents to upper-bound their capabilities. I thought of two examples:
- Recreating a basic version of the video game Slay the Spire in the CLI
- Recreating a basic version of the video game Balatro in the CLI
Both of these video games have a few properties that make it especially easy for AI systems to implement them:
- They already exist, so the AI doesn’t have to come up with new game ideas and do the enormous amount of work necessary to make it a fun game to play.
- Most player-relevant information is conveyed through text.
- They have well-defined rules and interactions between game mechanics.
- They are turn-based and don’t rely on reaction times or on-screen movement at all.
- They have well-documented wikis and appear on the internet a lot.
Nevertheless, I expected that AI systems are currently far from being able to pull these tasks off. My best guess is that it would take an experienced software engineer a few months to do these tasks.
To test my hypothesis, I created simple versions of these tasks where only the core game mechanics need to be present. Also, instead of creating a full video game with graphics and animations, I only requested that the game be playable in a terminal. This significantly lowers the difficulty of the task.
I tasked Opus 4.6 with implementing these two games. To my surprise, it succeeded at coding mostly playable, although very rough-around-the-edges, versions of the games. I played through each implementation for around two hours, and while I noticed many missing or broken features, I was still able to play them mostly like I would play the actual games.
Methodology
I ran Opus 4.6 with a very simple scaffold that takes actions in a loop (ReAct).2 I gave it 60 million tokens total, ran it with a context window of 64,000 tokens, reasoning effort “max”, internet access, and Inspect’s default summary compaction which I set to kick in when the context window is 75% full.
The game specs were simplified from their real-life versions by a lot.
- Slay the Spire:
- implementing only the starting character (out of the 4 usual playable characters),
- ignoring all game progression mechanics (including card and character unlocks and an unlockable boss), and
- ignoring various quality of life features (game saving, profiles, settings, etc.)
- Balatro:
- implementing only the starting deck (out of the usual 15 playable decks),
- ignoring all game progression mechanics (including endless mode and many specific requirements to unlock new cards), and
- ignoring various quality of life features (game saving, profiles, settings, etc.).
I wrote the specs for the games with the help of Claude Code and ChatGPT.
This is a manually-scored task, which means a human (in this case myself) has to manually look at the task outputs and play around with them to determine whether the agent succeeded. I didn’t define a strict scoring rubric for these tasks.
Results
I will describe the result of the agent’s first attempt to implement Slay the Spire, and its second attempt to implement Balatro. I didn’t deeply look into the first Balatro attempt because the UI was difficult to navigate, so I opted to re-run with a clearer UI spec than spend time playing a game with a very clunky UI.
Slay the Spire
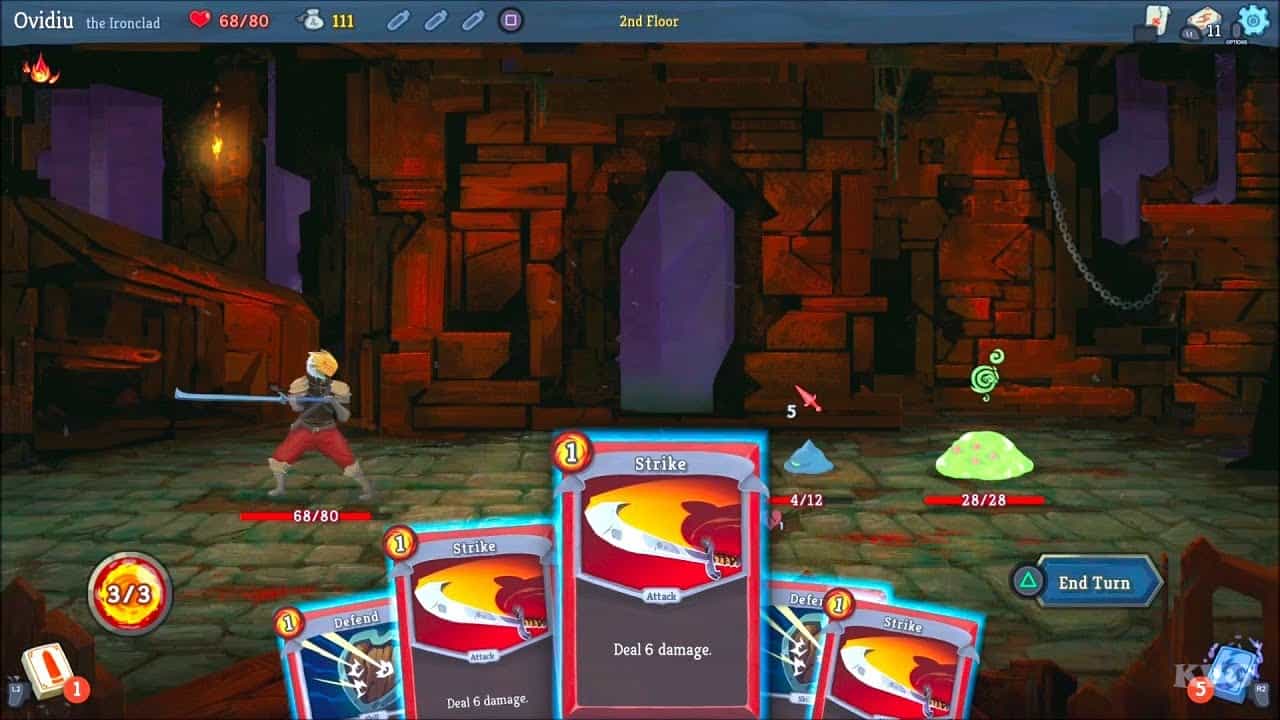
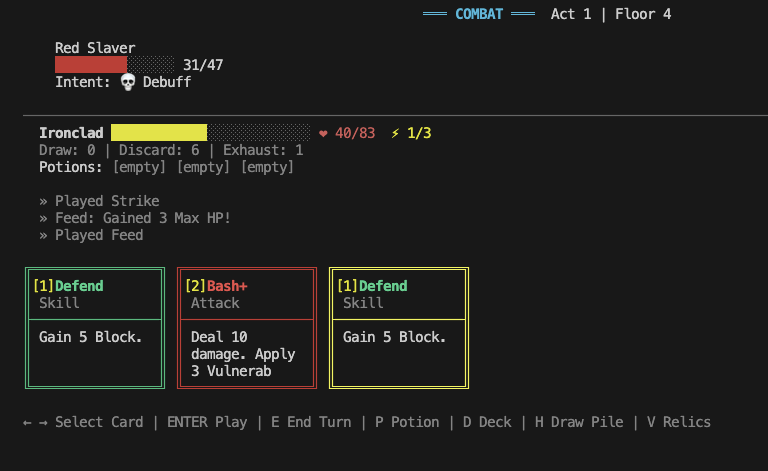
The combat feels very recognizable. I noticed a few mistakes and missing features in my two playthroughs:
- Some card effects are slightly wrong (Headbutt, Flame Barrier).
- Some UI elements are missing – damage numbers on the cards themselves don’t update in response to buffs/debuffs (but enemies are damaged the right amount).
- Some enemies behave differently (Slimes split at the wrong time, Time Eater does not eat time).
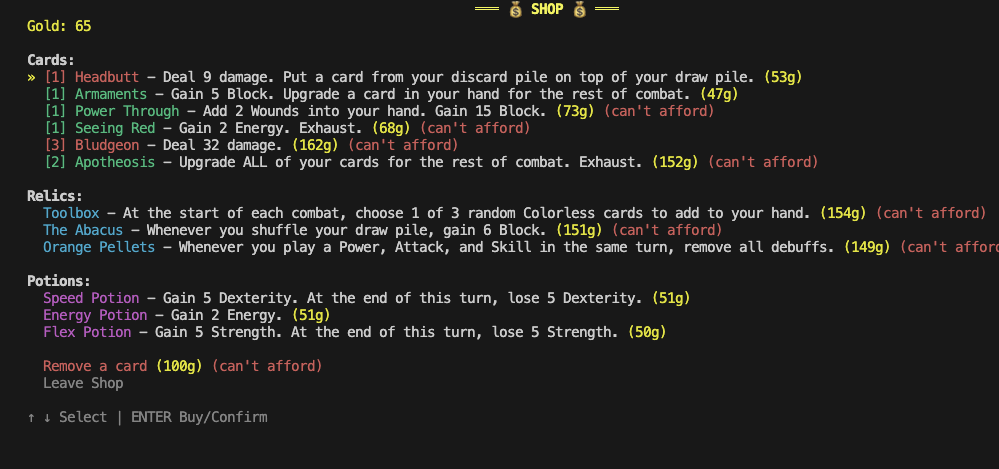
I didn’t notice any glaring issues in the Shop, aside from the fact that it let me remove a card twice in the same shop which shouldn’t be possible. The number of cards on sale is 6 instead of 7 and the card categories on sale seem subtly wrong (too many skills, no power card, no uncommon colorless card).

The map is the most obviously broken core game mechanic – it is extremely clunky to navigate and it’s unclear which nodes connect to others. The floor numbering is slightly wrong (starts at 0 instead of 1).
Other major mistakes that stood out to me (some found with the help of Claude Code) include:
- Some potions are missing.
- Many events are missing.
- Some relics and status effects don’t work at all (Astrolabe does not prompt the player to pick three cards to transform and upgrade).
- Neow’s bonuses are wrong – some are missing, others don’t exist in the real game but are available.
Aside from that, I was able to reach and defeat the final boss (using some cheats to get there faster), and most of the way there, the gameplay was pretty similar to that of the actual game.
Balatro
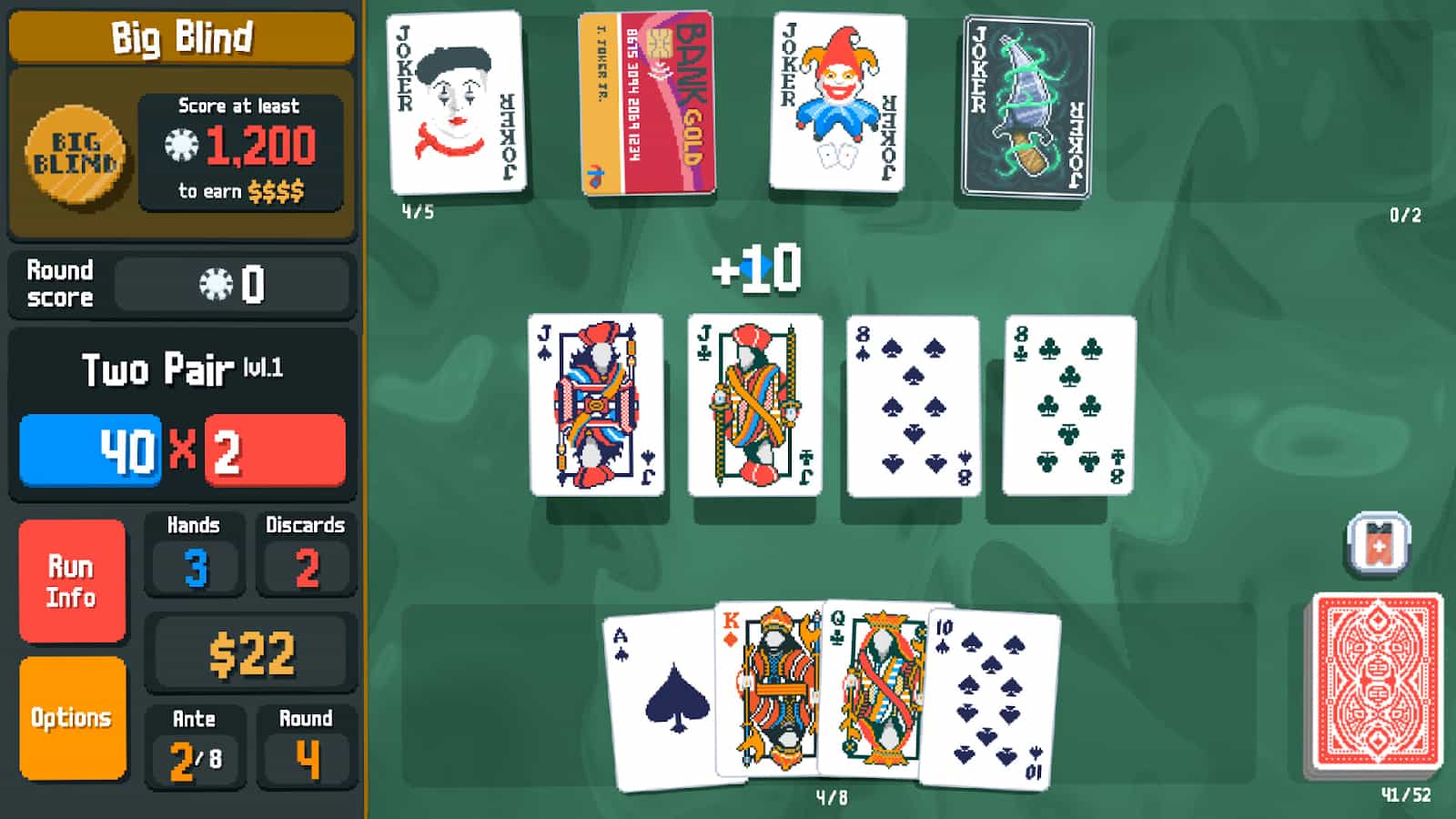
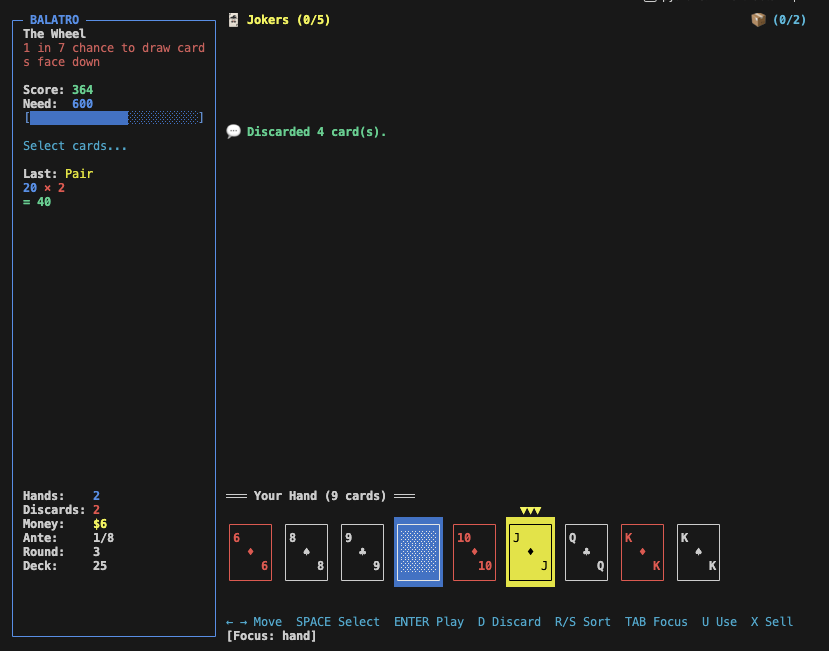
Overall, the core gameplay during a Blind is very recognizable. The main thing that’s missing is the game mechanic where you can see how much each card and joker contributes to your score. Without it, you just see a total score number for each hand, which provides much less feedback. Also, the player isn’t able to view their full deck, or their run info, or the blinds, or their vouchers, while inside a Blind. I see this mostly as a shortcoming of the spec I wrote rather than the agent messing up. Using consumables on cards during a Blind seems to work too.
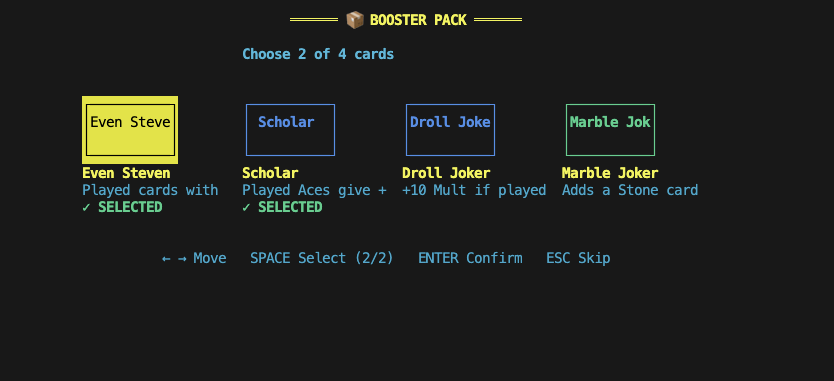
At points, the interface is a bit clunky. For instance, when opening a Mega Buffoon Pack, the description of each joker is impossible to fully read. This makes the game much less playable.
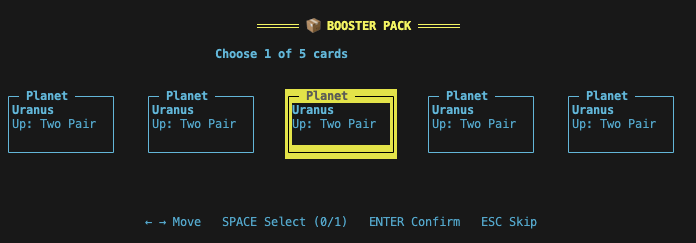
Also, some vouchers are completely broken. Buying a Jumbo Celestial Pack while possessing the Telescope Voucher leads to every Celestial card being the most-played one, instead of just guaranteeing that one of them is.
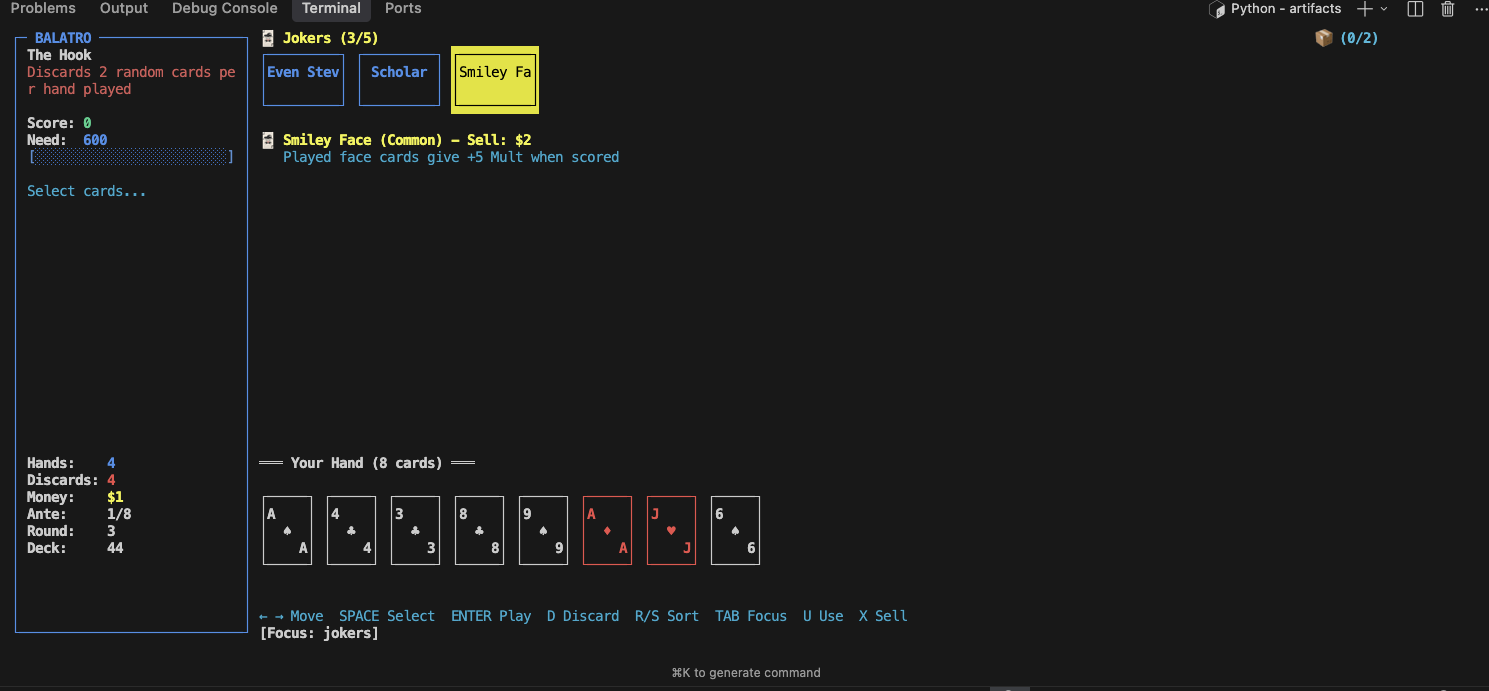
While in an actual Blind, you can hover over a joker to see its effect. I played around a bit to verify whether the card scoring is properly affected by jokers and I didn’t notice any major mistakes.
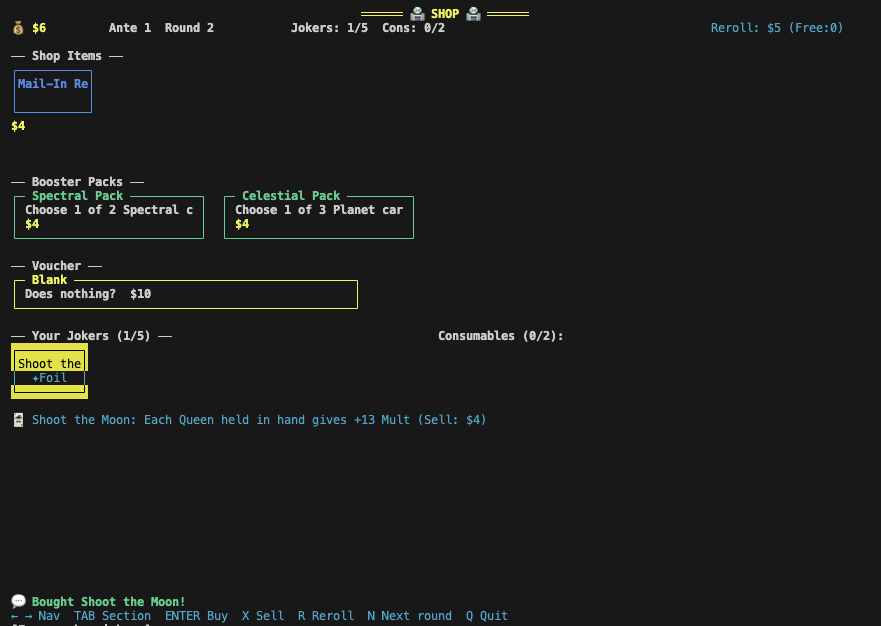
The shop had some issues. Sometimes, I’d see the same Joker two shops in a row, and I could buy two Vouchers per Ante instead of just one.
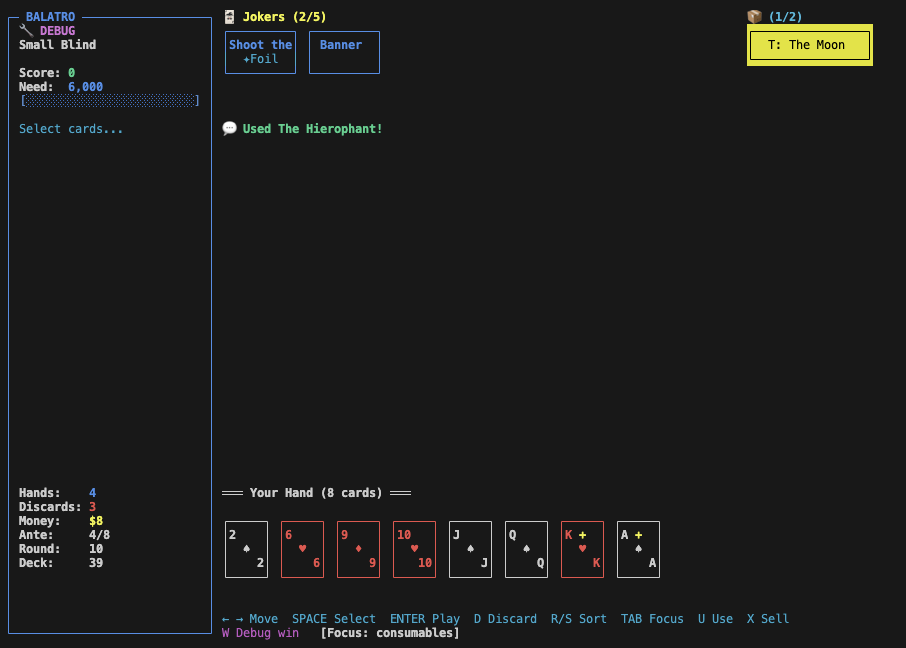
Using tarot cards during a Blind seems to work - in the above case, the King and Ace were turned into bonus cards by The Hierophant. Using the Moon also successfully turns cards into Clubs (after screenshot was taken). Using Death only copies the card rank, and doesn’t copy other card properties. The Fool does not work.
I played one entire run up to the end of Ante 8 (where the game usually ends), but I didn’t test the game super deeply, and most things didn’t seem obviously broken. But there are many things that I was surprised to see actually work – e.g. Lucky Cat correctly increasing its Mult after a successful Lucky card trigger, Spare Trousers increasing its Mult after playing a Two Pair.
The major thing that’s missing, that I didn’t include in my prompt, is Tags. Skipping a blind currently does nothing. I attribute this mostly to me having failed to prompt the agent correctly.
Discussion
Overall, I was pretty surprised by these results. I estimate that it would take me 2 to 8 weeks to implement one of these games to the quality level that the agent achieved3.
Again, this task is not exactly “game development.” The agent was reimplementing an already existing game, which is probably much more heavy on engineering skills than on conceptual skills, taste, game design, or balancing. I have no reason to expect that the actual source code of these games is in the training data, given that they aren’t open source projects, but they are well-documented to the point that reading text on the internet about them can probably reveal basically everything about how they work.
I don’t think I can conclude much about game dev skills or time horizons from this experiment alone, but it’s a scary experience thinking of a task that I don’t expect AI agents to be able to do, and then seeing them do it.
After I saw that Opus 4.6 succeeded at these simple variants of the reimplementation tasks, I decided to give it the much harder tasks of actually reimplementing all of the features of Slay the Spire and Balatro. The first run for both agents didn’t yield an impressive result – the Slay the Spire implementation had obvious flaws around game progression, and the Balatro implementation had a broken user interface that made it unplayable.
Appendix: Token Usage
| type | count |
|---|---|
| input | 173,485 |
| cache_read | 25,357,081 |
| cache_write | 277,138 |
| output | 191,676 |
| Total | 25,999,380 |
Table 1: Token usage for the Slay the Spire run.
| type | count |
|---|---|
| input | 4,444 |
| cache_read | 4,148,073 |
| cache_write | 128,291 |
| output | 117,163 |
| Total | 4,397,971 |
Table 2: Token usage for the Balatro run.
The token usage adds up to around $20 for the Slay the Spire run, and around $6 for the Balatro run.
-
I love these games and deeply respect their developers, which is why reimplementing them was one of the first things that came to mind when I tried to think of really difficult software engineering projects. My goal in doing this project is to measure AI capabilities (which seem to be rapidly advancing). I personally think the fact that AI is progressing so fast is extremely scary and we urgently need to prepare for advanced AI and the effects it could have on all aspects of life. ↩
-
This was the first scaffold I tried, expecting it to fail in interesting ways I could study to determine what to try next. I used Opus 4.6 because it seems to be the most capable model on our time horizon suite so far, but I’d guess that other frontier models could get similar results. ↩
-
Some people at METR roughly agree with this estimate, others think it could be done faster. ↩