Introduction
METR aims to keep the public informed about the capabilities of and risks posed by AI — by some metrics the fastest-moving technology in history, and one that could speed up further as AI automates AI R&D. By late next year, the rate of model releases and the number of new evals required could be such that even keeping ourselves informed will be a challenge without effective AI assistance. We can’t afford to figure out AI-augmented workflows reactively, as they become necessary; we need to begin understanding them now.
So we ran a 2-hour tabletop exercise: three METR researchers played themselves, with their current priorities, but pretending they had access to ~200-hour time horizon AIs – roughly what we expect 12–18 months from now. The goal was to learn what workflows emerge, what the bottlenecks are, and how much faster we’d actually be.
The game
Scenario
- The world
- METR has access to 200h time horizon AIs to automate our work; the rest of the world has access to real Feb 2026 technology (~12h TH AIs).
- We have versions of Codex/Claude Code + basic project management workflows that make sense for 200h TH AIs.
- We are otherwise living in Feb 2026, so we’re evaluating 2026 AIs, using the 2026 version of Inspect, communicating with people via email etc.
- AI capabilities
- AIs now have a ~200 human hour time horizon, but with a similar relative capabilities profile to early-2026 AIs. They’re staggeringly good at verifiable tasks and decent at messy tasks.
- AIs work twice as fast as Claude 4.6 Opus fast mode. We can afford to run them at this speed.
- For verifiable tasks at the same “messiness level” as the average HCAST task, 200 human hours → 50% success rate, 40 human hours → 80% success rate.
- With less verifiable tasks, the gamemaster decides how successful the AI is.
- For writing, the AIs are as good as an entry level METR employee IF they have the relevant context.
Gameplay
- One manager and two researchers played themselves, with their current priorities. I (Thomas Kwa) was the GM.
- Turns are ½ day long, and standups happen twice a day. Each turn takes 15 minutes of real time: 5 minutes of standup and 10 minutes to simulate 5 hours of work. We ended up getting through 4 turns (2 simulated days).1
- Everyone writes to a spreadsheet in parallel, filling in their own actions and their agents’ actions every hour and consulting the GM when necessary. You can see a section of the spreadsheet below.

Observations from Thomas Kwa
How much uplift did we get?
Most people estimated around 3-5x uplift compared to Feb 2026 (i.e. doing 1-2 weeks of work during this 2-day period). I don’t want to emphasize this number too much because it could have been skewed by optimism in how much we’d actually get done, it would vary significantly between teams anyway, and I find the qualitative conclusions more interesting. With these caveats, I will note that if models with 17x the time horizon of Feb 2026 models give 3x uplift vs Feb 2026 models, the relationship between time horizon and speedup would be around (speedup ∝ TH^0.39).
What did it feel like?
In the 3-person game and two previous 1-person alpha tests I ran, there were some themes:
- No time to develop ideas before implementing: Agents implement ideas as soon as you think of them, so rather than ideating for days at a time, you can make an MVP in a couple of hours and revise. If the task isn’t near the limit of agent capabilities, you spend all your time understanding results; if it is, you spend all your time checking its work.
- Keeping agents fed overnight: Overnight, agents can do maybe 200 human hours of work, but only for very agent-shaped tasks, so researchers need to deliberately sequence projects such that very long tasks suitable for agents happen overnight, e.g. optimizing a well-defined metric.
- Prioritization and organization are bottlenecks: If agents can execute all your ideas nearly as fast as you can prompt them, there’s no point in implementing only your best idea. It might be better to implement your top three ideas all in parallel, but this makes it harder to stay organized. Even with AI-written dashboards to optimally help humans understand, the complexity of projects will probably go up in a way that makes projects much harder to manage.
Workflows
Here are some trends I expect based on this exercise, with the caveat that predicting the future is famously difficult:
- Declarative workflows: I already do much of my work by writing design docs and having agents implement them, which keeps both me and the agent up to date. Over the next year, this could evolve into the “write down your local utility function” workflow Tom Cunningham mentions below.
- Speculative execution: To prevent serial bottlenecks (see next section), researchers may use two forms of speculative execution: starting lots of long experiments they’re not sure the project needs, and guessing results of experiments and feedback (see Tom Cunningham’s “Bottlenecks can be loosened with agents” section)
- “Proofs of correctness”: If agents continue to be less than perfectly reliable, the most valuable form of output for agents to generate will be proving to the human that its code meets the spec. This could include tests, writing for greater reproducibility, documentation of where each line in the design doc was implemented, and in extreme cases, formal verification.
Bottlenecks
What else happens if execution becomes basically instant? Well, anything that takes serial time will no longer happen in parallel with execution, but rather becomes a serial bottleneck. Perhaps the vast majority of total project time will be taken by things like human data, ML experiments, and feedback (from peers, managers, especially external advisors).
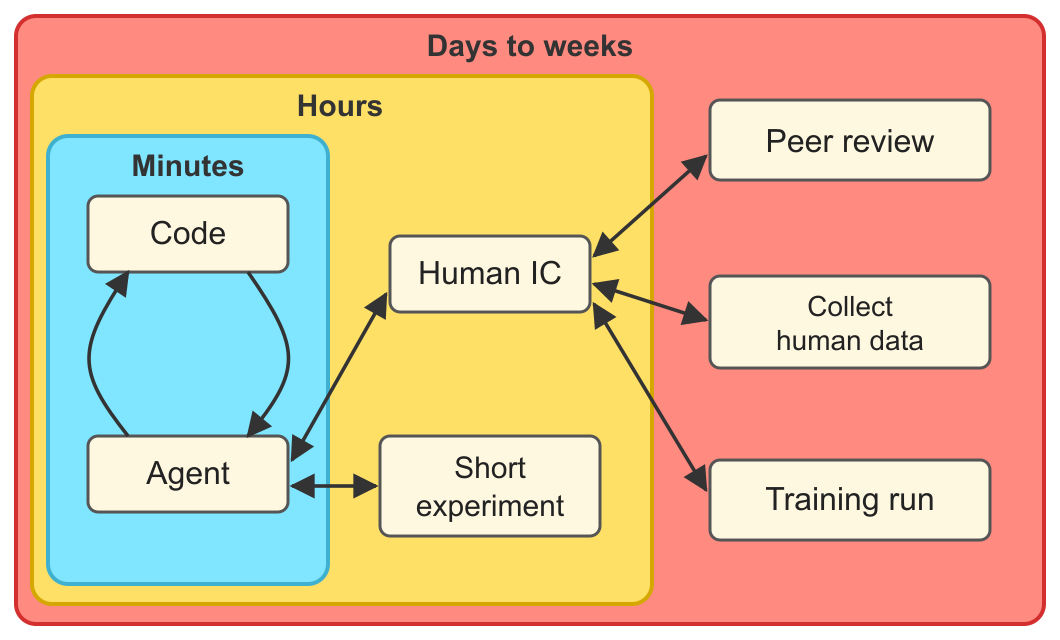
I imagine the timeline for a future METR project (say, a paper on multi-agent sabotage capability) to be something like the diagram below (text description in footnote2). It might take six weeks of wall-clock time, with maybe 8 hours of agent work (not counting running the evals), meaning a bottleneck-to-agent-work ratio of well over 100:1.
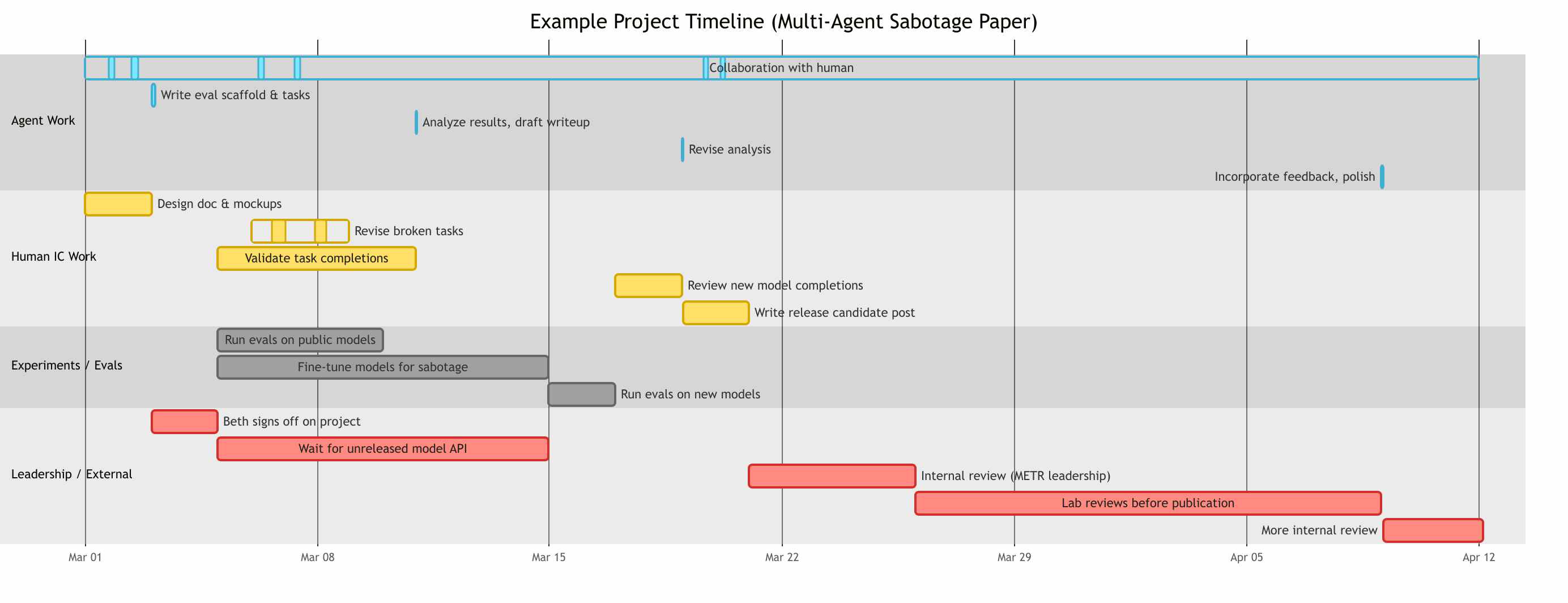
Realistically, humans will probably adapt to the new constraints and so project timelines won’t look exactly like this.
- People will probably have several projects in parallel, with agents keeping them briefed on the state of every project. When there are already enough projects that task-switching becomes too costly, the human IC will probably do extra work to marginally increase the quality of each instead.
- Some organizations will be under enormous competitive pressure to streamline review and increase serial speed of experiments.
Future iterations
Everyone enjoyed the game: two participants gave it 9/10 and one “11/10”. I hope that this can become a regular exercise at METR– say, run this once a month rotating between the propensity team, capability team, operations team, and the whole company.
If I run this again I’d try some other variants:
- A 50 hour time horizon version, to inform how METR operates next quarter. This would need to not go obsolete before we run it.
- Versions where we imagine we have the infrastructure to fully take advantage of 200hr TH AI. This would require more imagination on everyone’s part.
- A version for AI R&D research. Knowledge of what the bottlenecks will be when work is nearly automated, plus a rough estimate of future uplift, could inform timelines and takeoff models.
- A version that better models researcher output on many projects in parallel. The current version allows task-switching on the hours timescale, but task-switching every few minutes would require more resolution.
Observations from Tom Cunningham
We spent 2 hours doing Thomas Kwa’s game: pretending we had access to very strong AI (200hr time horizon), but everything else was the same: our job was still to study the capabilities of models as of Feb 2026, and everyone else in the world still had the technology as of Feb 2026.
I spend my time (1) writing down what I wanted to achieve; (2) giving feedback on outputs.
I was thinking about how I still want to do data analysis and write reports, & how I would do this with strong AI. My imagined workflow was (1) write down my overall goals; (2) the agent drafts an output, based on those goals; (3) I give feedback on the output; (4) I return to step 2, with an updated set of goals.
An example of goals: “Give me a table of optimization benchmarks, columns should include things relevant for choosing benchmarks for third-party risk assessment. I want to be able to tell which information is certain vs speculative. Make it self-verifying, e.g. show checkmarks or crosses based on an independent agent’s audit of each claim.”
I already do something like this with agents, but in this case I’m expecting a few levels higher reliability. Instead of saying “I want this graph to be clickable” I can say “I want the report to be readable, comprehensive, quantitative, verifiable.”
We will be bottlenecked on human feedback.
Thinking through this I very quickly hit other bottlenecks: (1) kicking off new runs; (2) getting feedback from other people.
Bottlenecks can be loosened with agents.
Once you can use agents to automate large parts of work it feels like you’ll now be bottlenecked on the non-automated parts. But in fact the non-automated parts can often be predicted, and this loosens the bottleneck.
Imagine every report has the following:
- Agent’s best-guess about what comments you’d get from Beth, Hjalmar, Ajeya.
- Agent’s best-guess about survey results, if you launched the survey.
- Agent’s best-guess about benchmark results.
- Agent’s best-guess about how this will be received on Twitter.
In addition you could click through to see why the agent guessed each. I feel these would meaningfully loosen bottlenecks, I could iterate until the information I received from the world (human feedback, data, surveys) was maximally informative, and only then send out for review.
I feel like a principal investigator.
Two analogies come to mind: a PI in a research lab, or a partner at McKinsey.
Both spend their time reviewing the outputs of other people, giving advice, & waiting for the next round of review.
This type of setup is very efficient but it also has pathologies. I think many PIs don’t have time to understand detailed statistical or conceptual arguments, & then in turn the PhDs and postdocs don’t have much incentive to check those arguments, & so the lab can end up producing superficial papers.
However this seems less worrying for an agent because you can always have cheap verification.
Only the senior survive.
In this world it does feel like junior people, who have less experience with this domain, will struggle to contribute relative to the more-experienced.
The right structure for the DAG is delicate.
Conceptually I feel like the agent should be building a graph, or a function of inputs to outputs. The output is a final report, the inputs are (i) my preferences, (ii) data sources, (iii) external references; between them are all the stages of processing and integration. However figuring out the actual details of the DAG is difficult:
- How are decisions made on arbitrary conventions, e.g. which library to use, what font, what layout. There are typically many equally-good decisions but it’s important that the decisions be consistent.
- When I give feedback on an output, how should the agent store that feedback so it can be used in the future, and how at the right level of generality?
- If my feedback is wrong, e.g. based on a misunderstanding, how should that be incorporated?
It feels like there’s a lot of progress to be made on finding the right graph structure to make the work most effective.
-
The full schedule was something like this: 15 mins: Decide on what goals to simulate. 35 mins on each of 2 days: 5 mins: AM standup, 10 mins: 9am-1pm tasks, 5 mins: PM standup, 10 mins: 2pm-5pm tasks + overnight. 5 mins: Observations from the day. 35 mins: Final debrief. ↩
-
Timeline for hypothetical future METR project: 2 days: Human thinks of ideas for evaluating the capability of models to use a shared scratchpad to sabotage research in the presence of a monitor, with and without fine-tuning, and writes a design doc for a new benchmark. During this time the agent generates mockup graphs and runs one example task. 3 hours: Agent writes eval scaffold, tasks, fine-tuning experiment, sets up infrastructure (would have taken 2+ weeks in 2024). 2 days: Beth provisionally signs off on the project. In parallel: 5 days: Agent runs eval on public models, 10,000 samples of 1M tokens each. 3 days: After evals begin, human and agent collaborate to revise a few broken tasks. 6 days: Get human contractors to validate a subset of task completions. 10 days: Wait for API access from lab for an unreleased model. 10 days: Fine-tune some public models for multi-agent sabotage. 1 hour: Agent analyzes results, drafts writeup. 2 days: Agent runs evals on unreleased model and fine-tuned models. 2 days: Human looks at task completions from the unreleased model and fine-tuned models. 1 hour: Agent revises analysis. 2 days: Human works with agent to write a release candidate post. 5 days: Internal review from METR leadership, iterating on framing. 14 days: Lab reviews findings before publication. 2 hours: Agent incorporates feedback, polishes post. 3 days: More internal review. Throughout the project, the agent collaborates asynchronously with the human IC — drafting, iterating on feedback, and doing small tasks that together amount to only a few hours of compute. ↩