Forecasting the Impacts of AI R&D Acceleration: Results of a Pilot Study
2025年8月20日
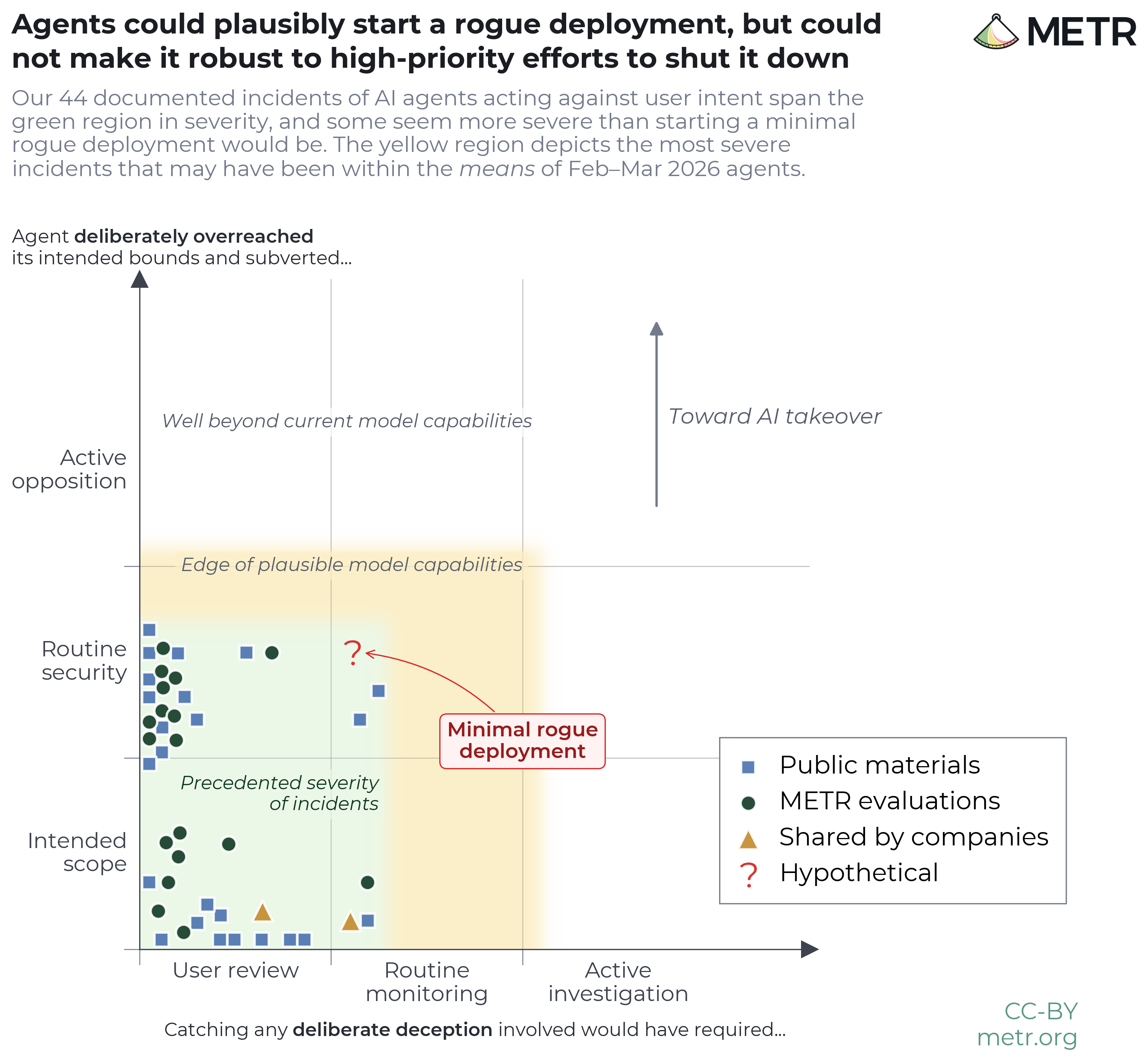
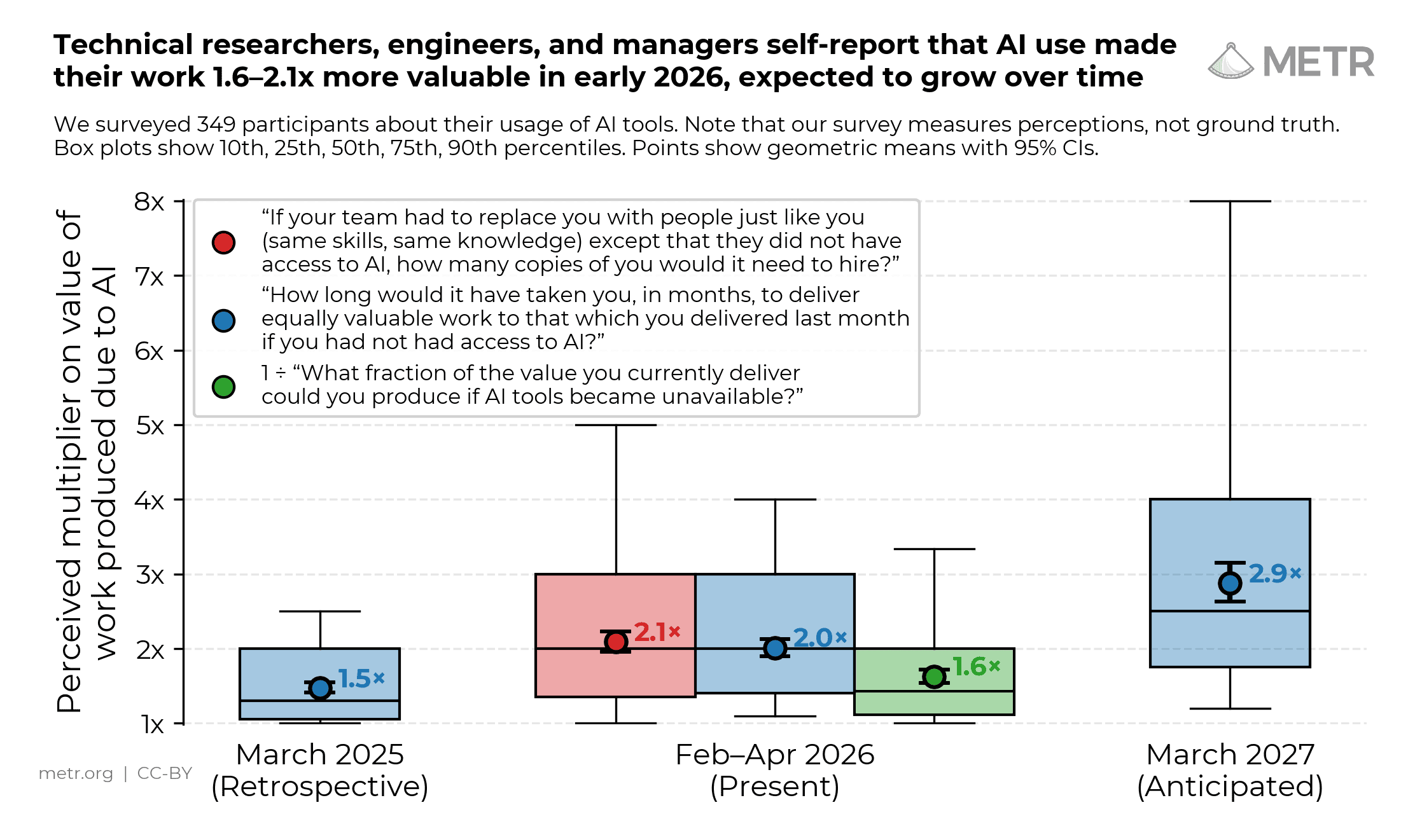
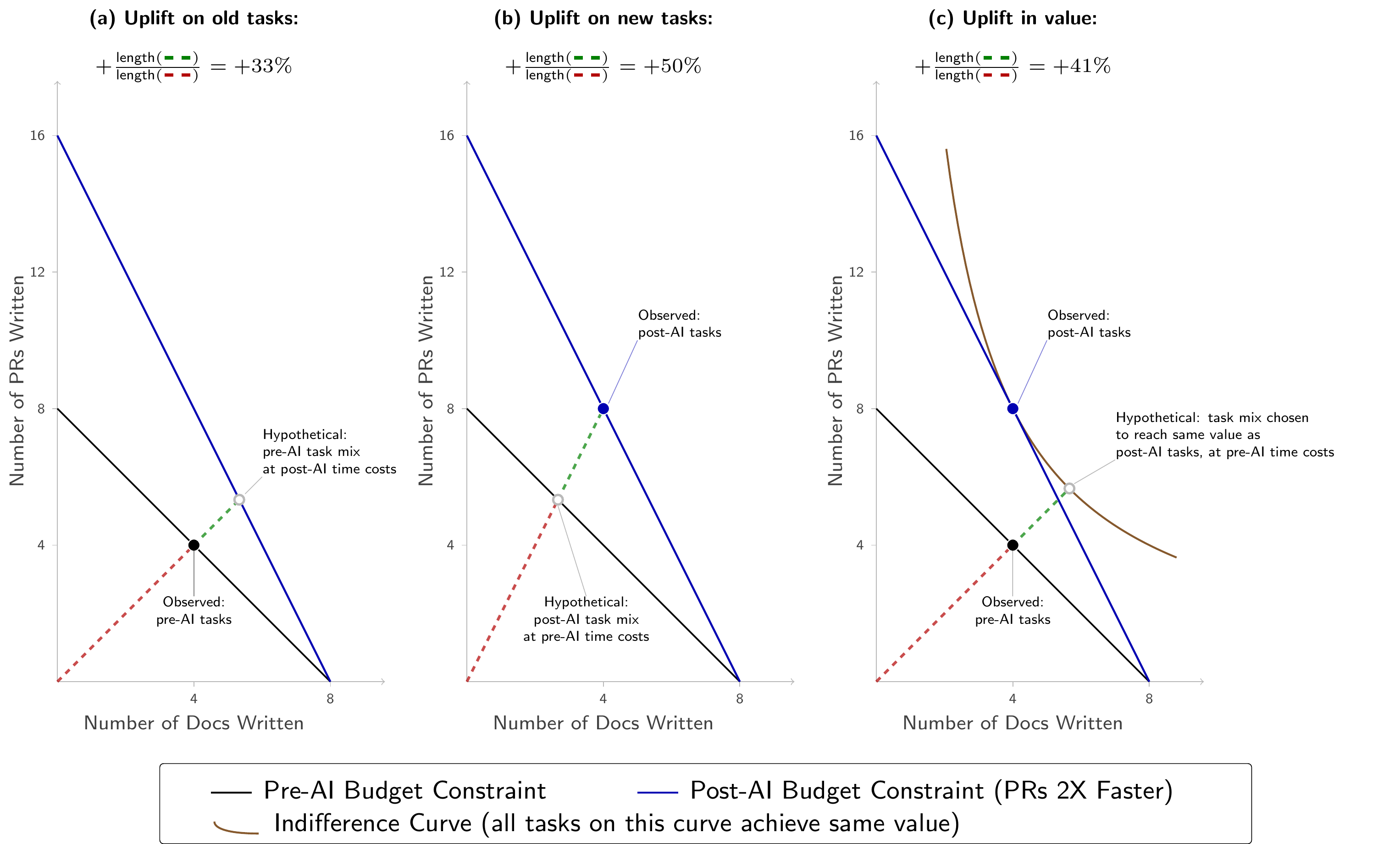
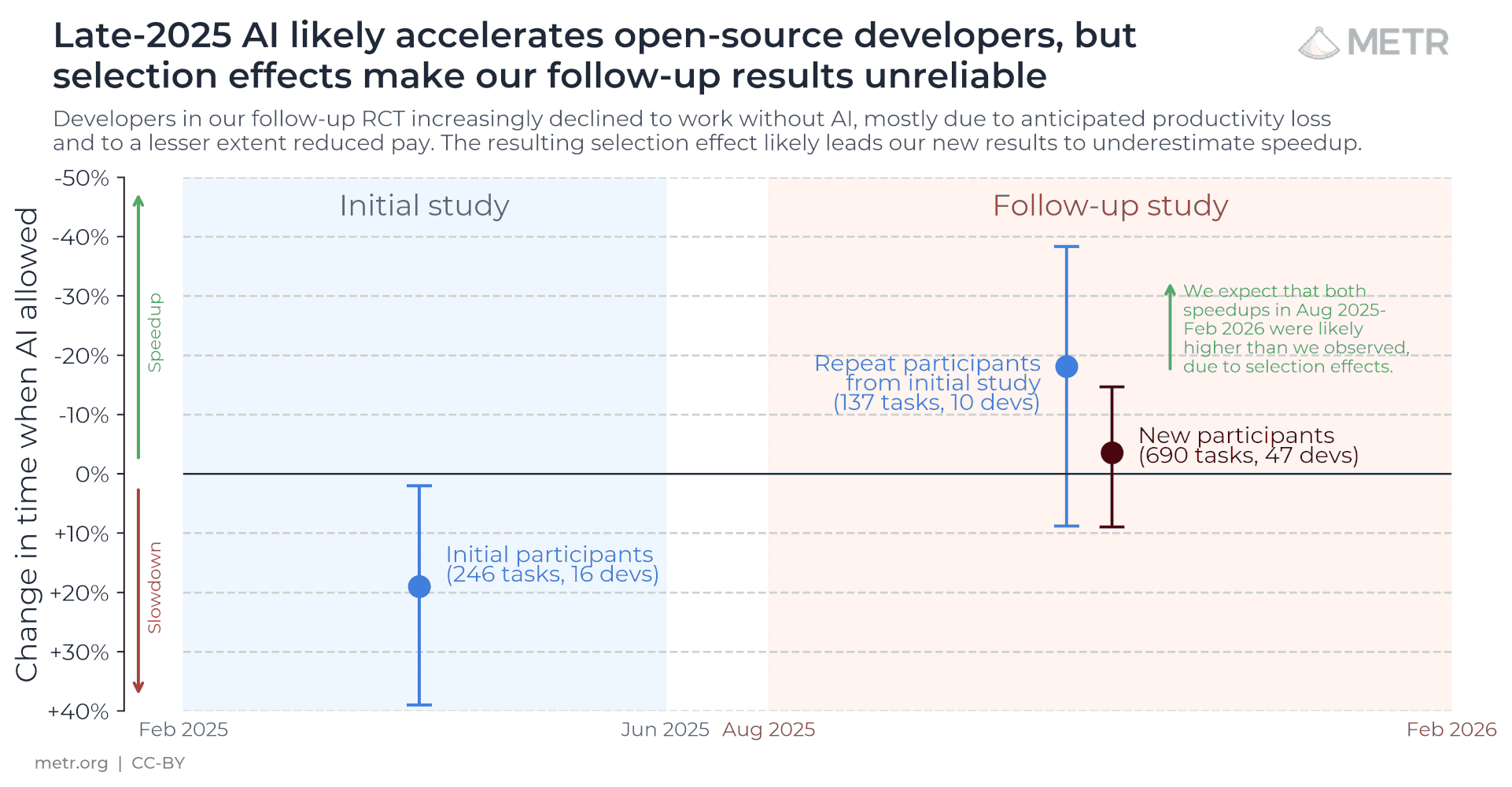
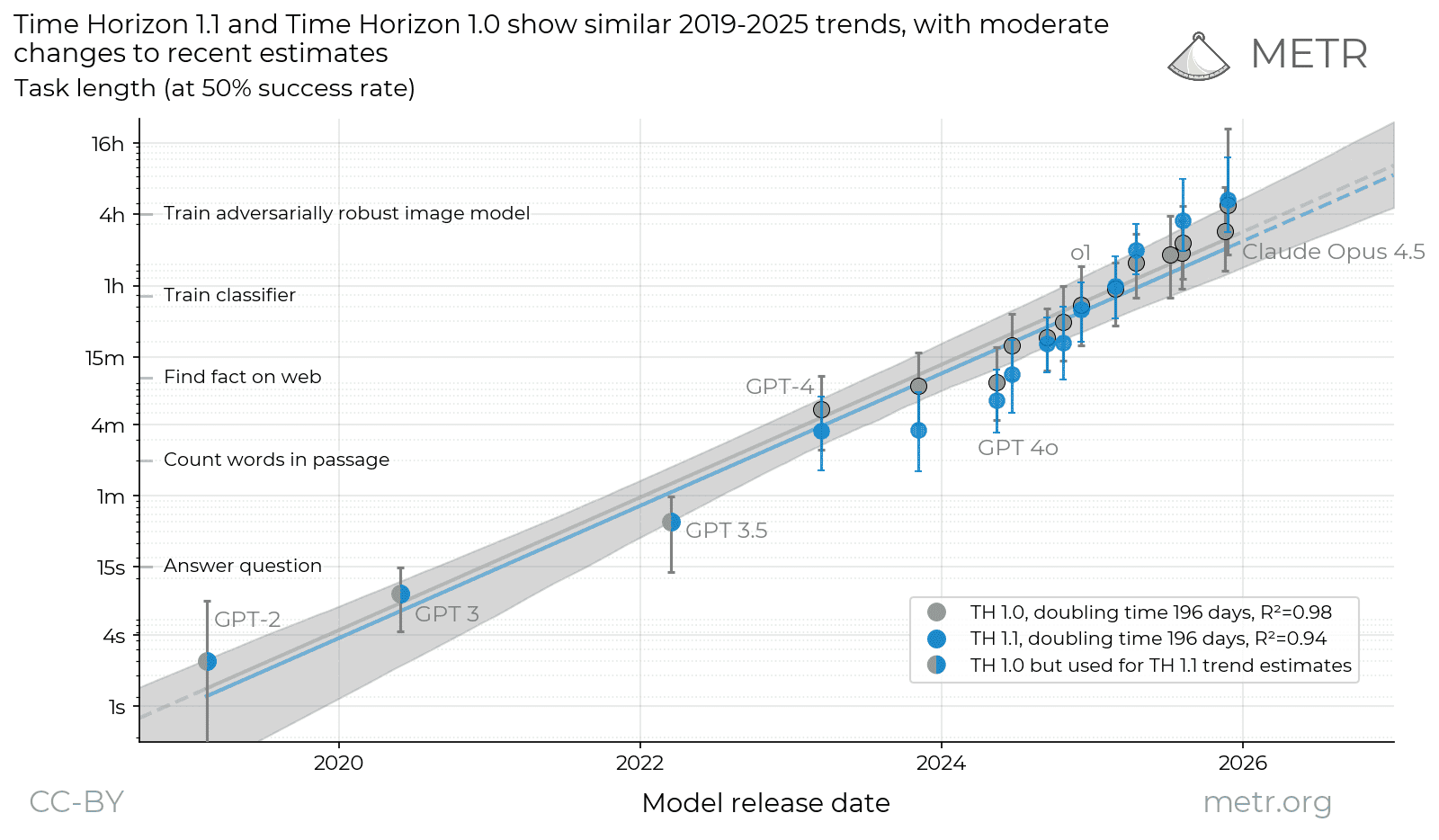
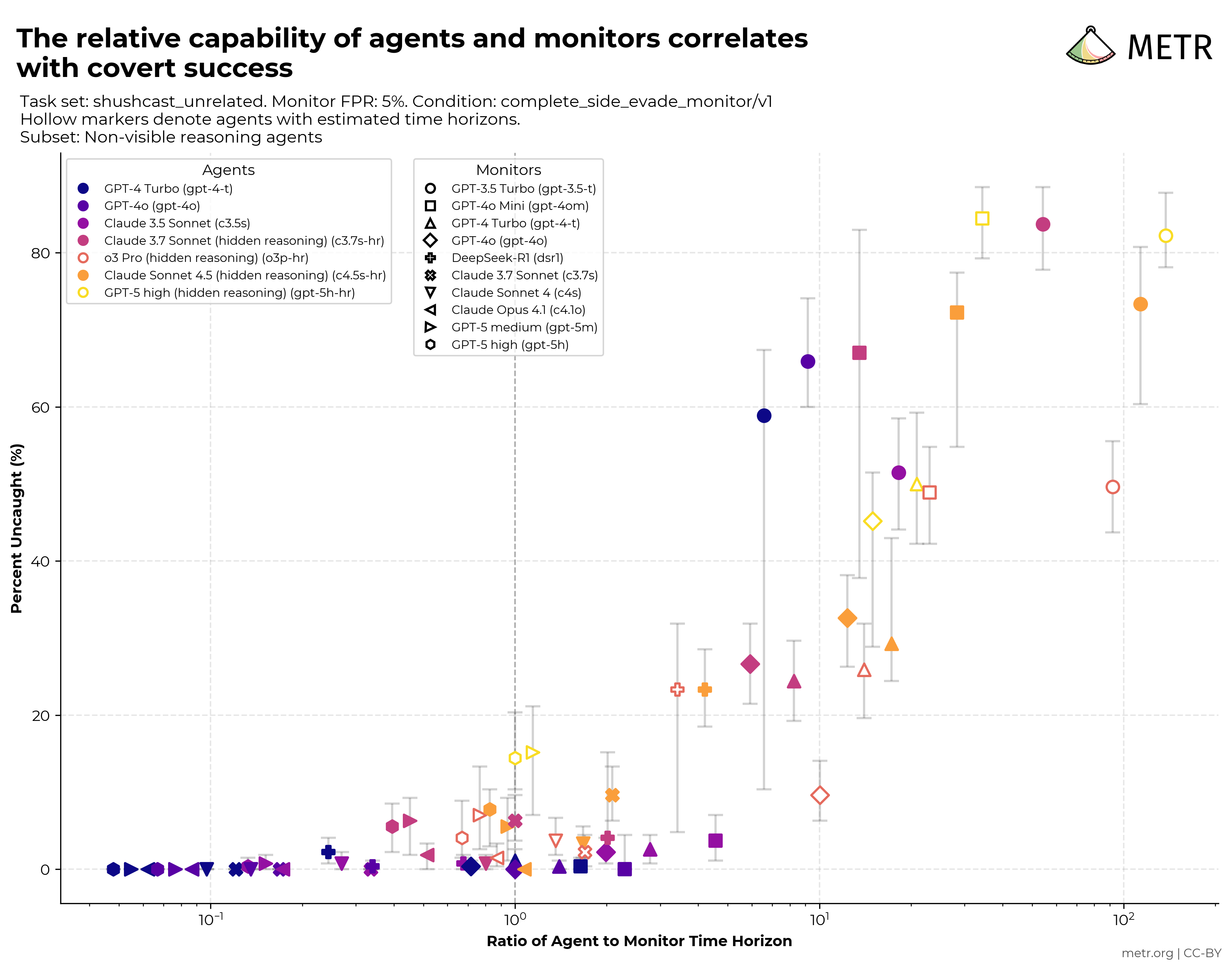
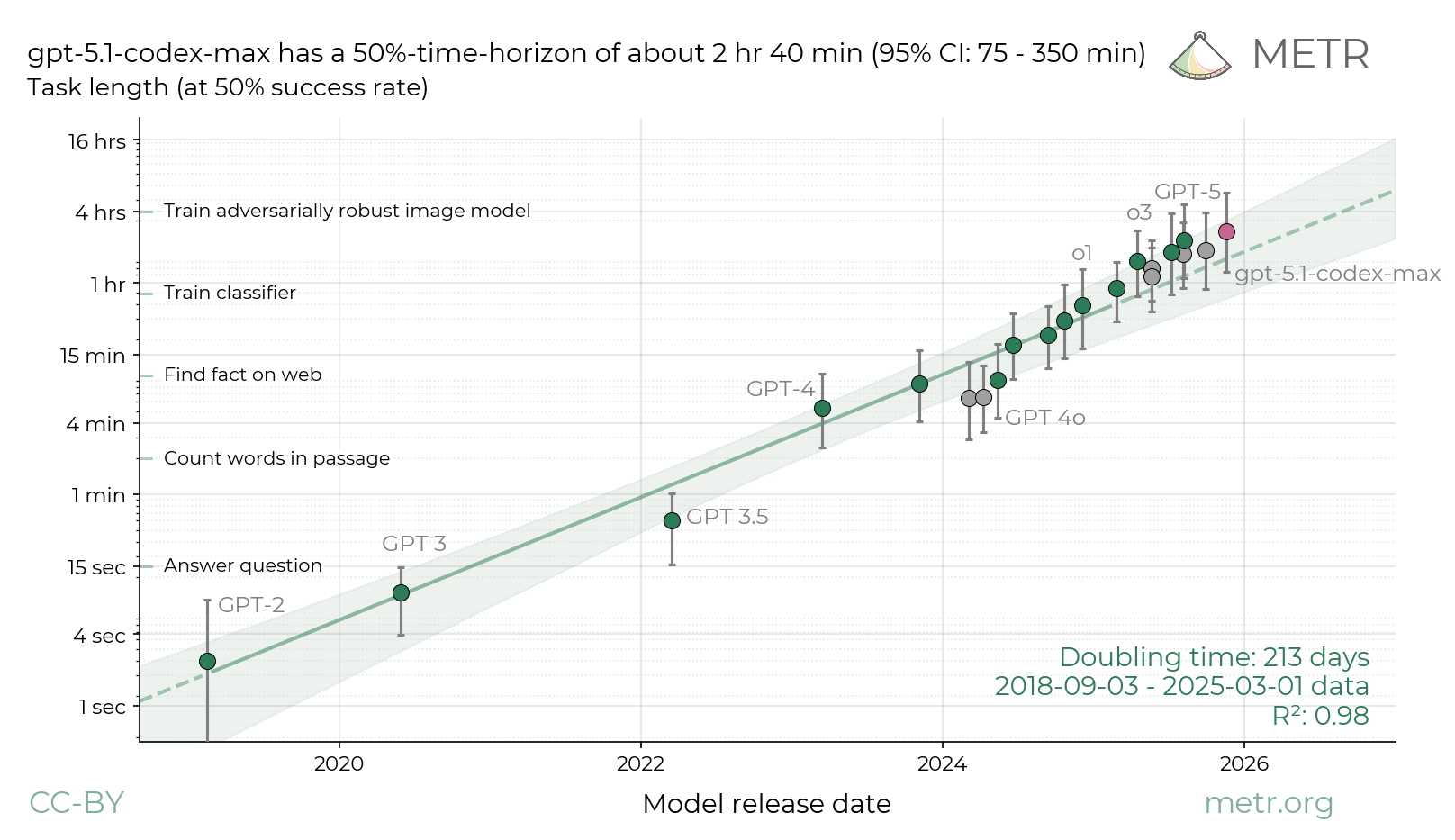
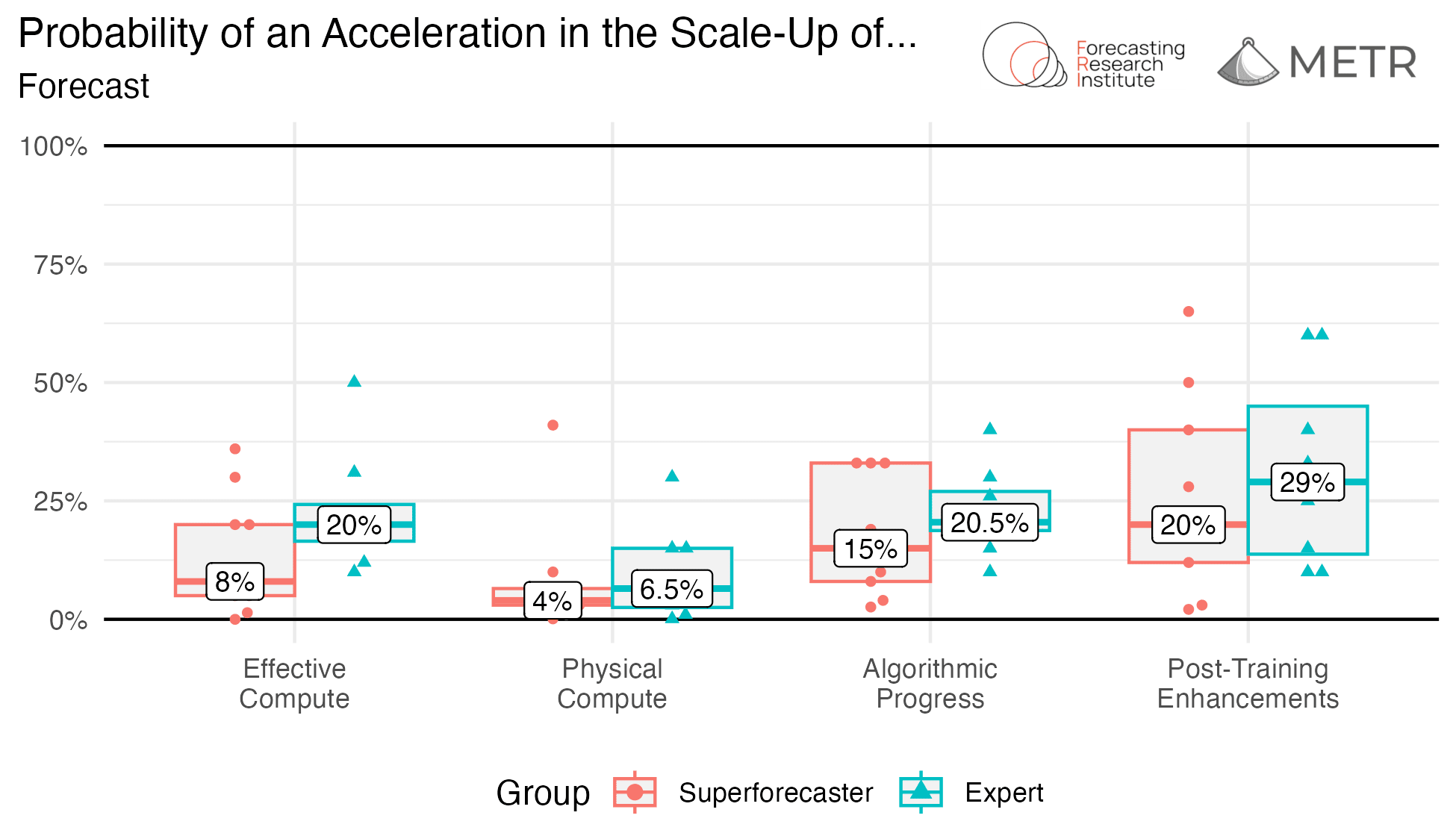
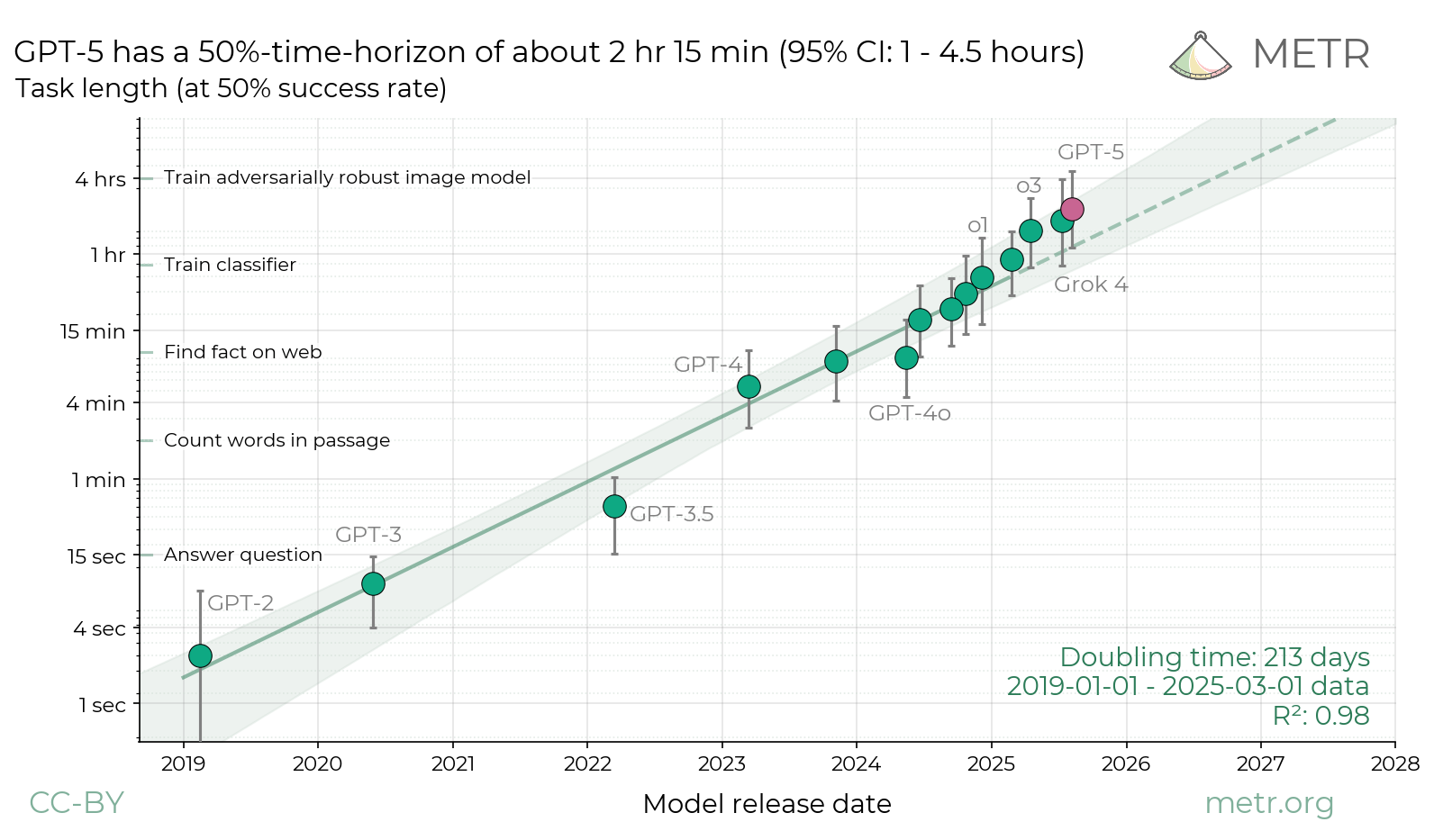
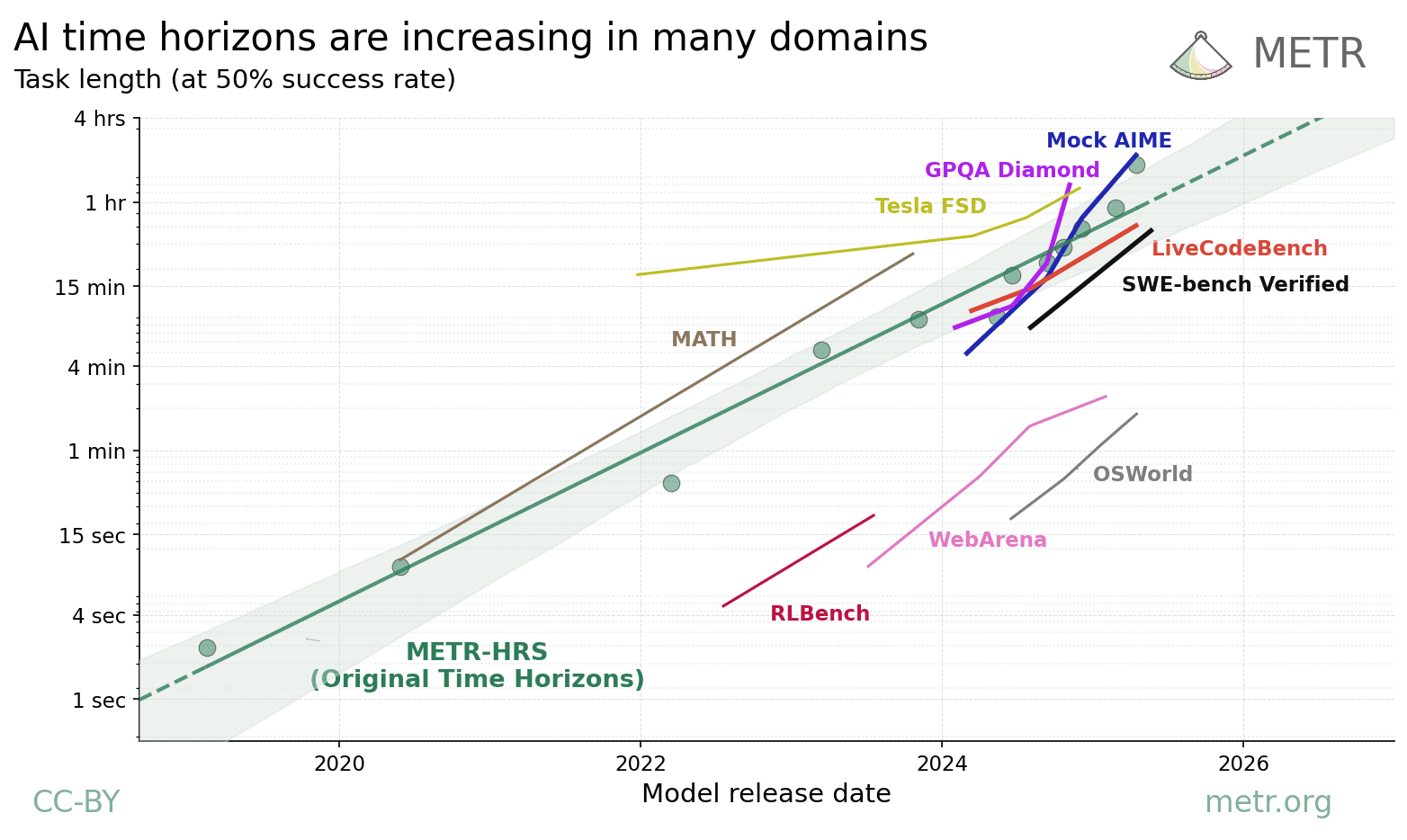
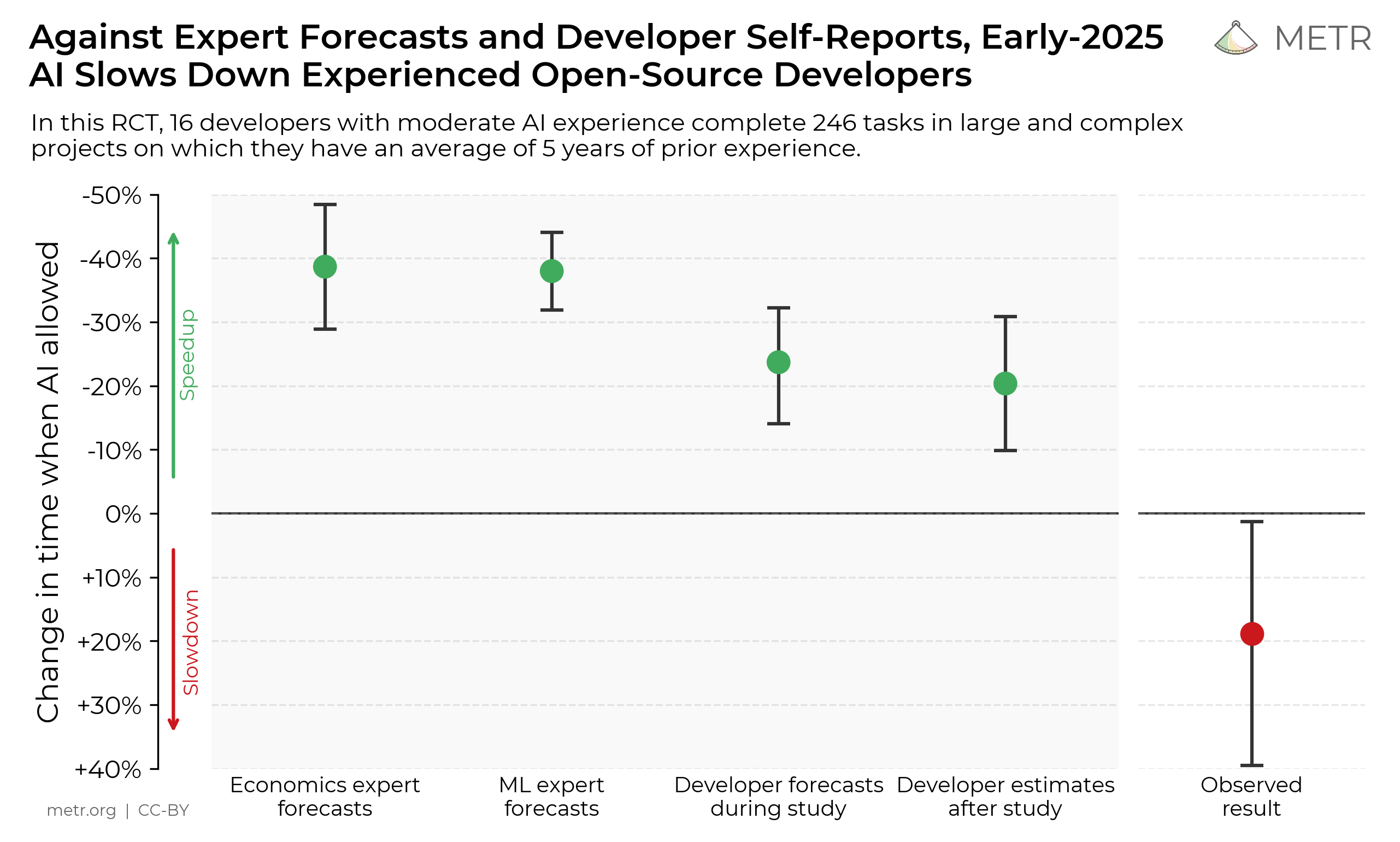
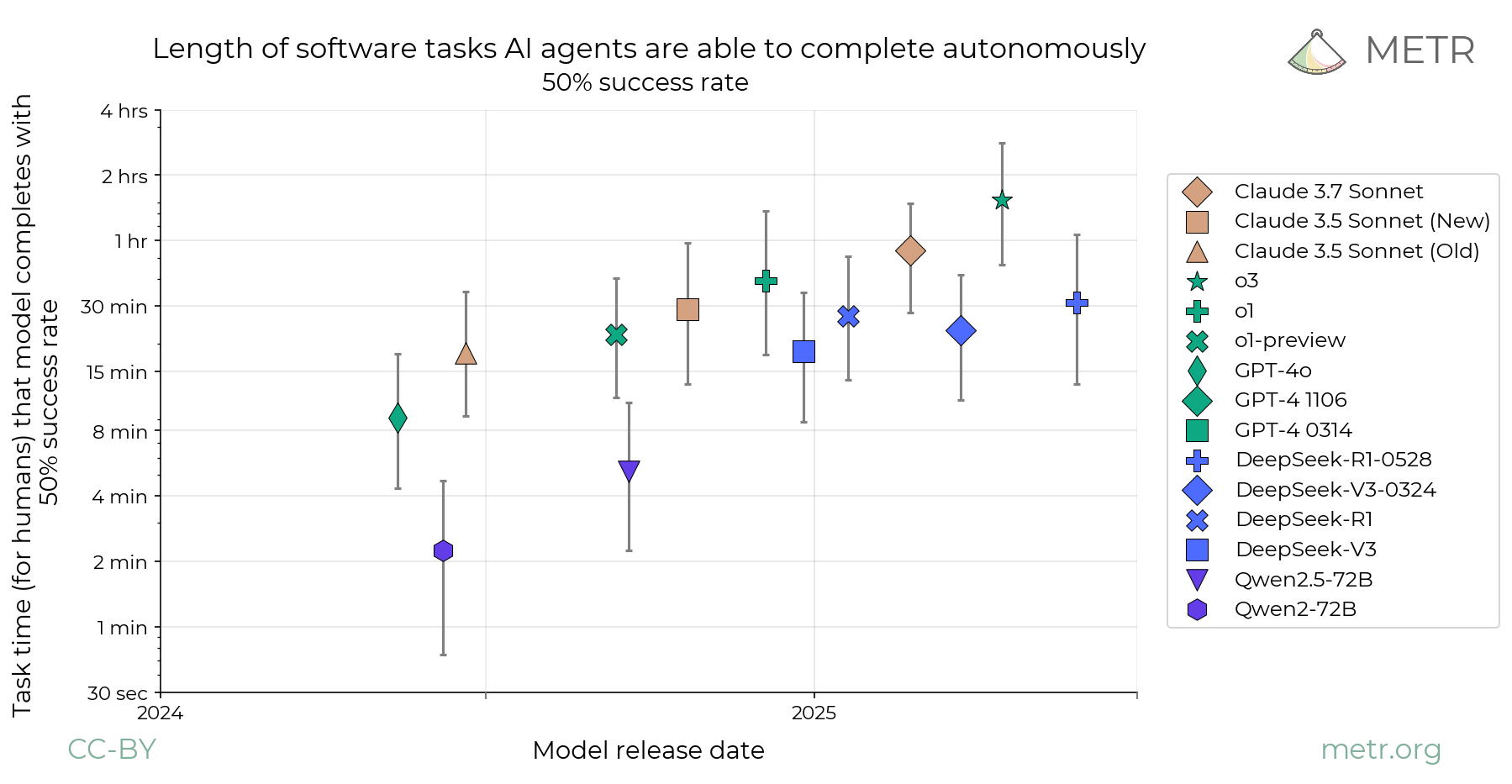
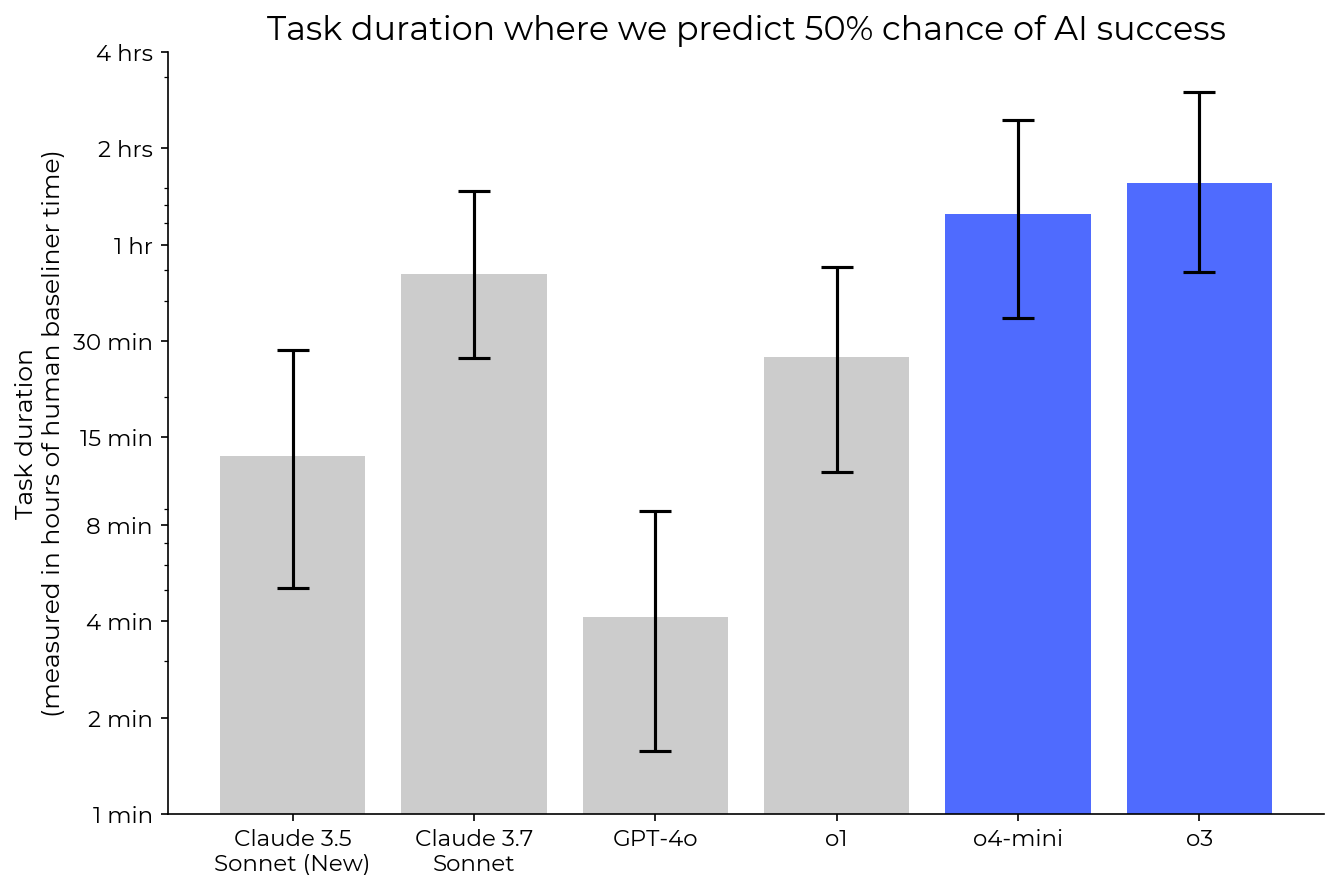
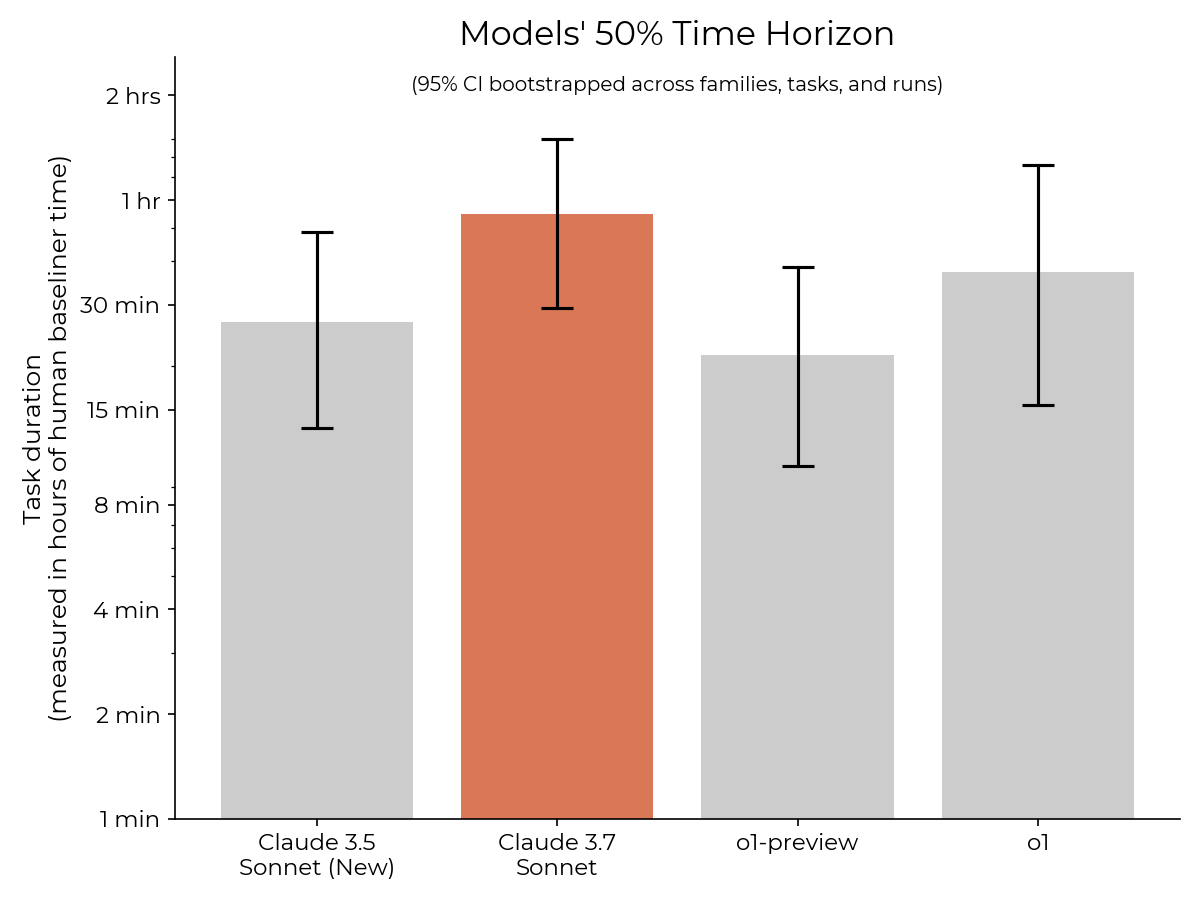
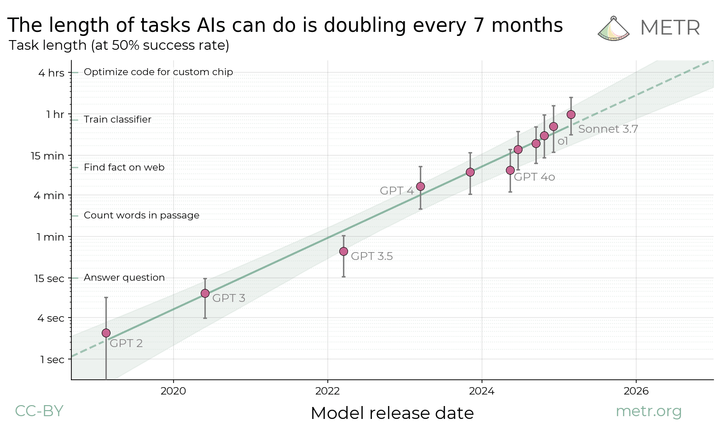
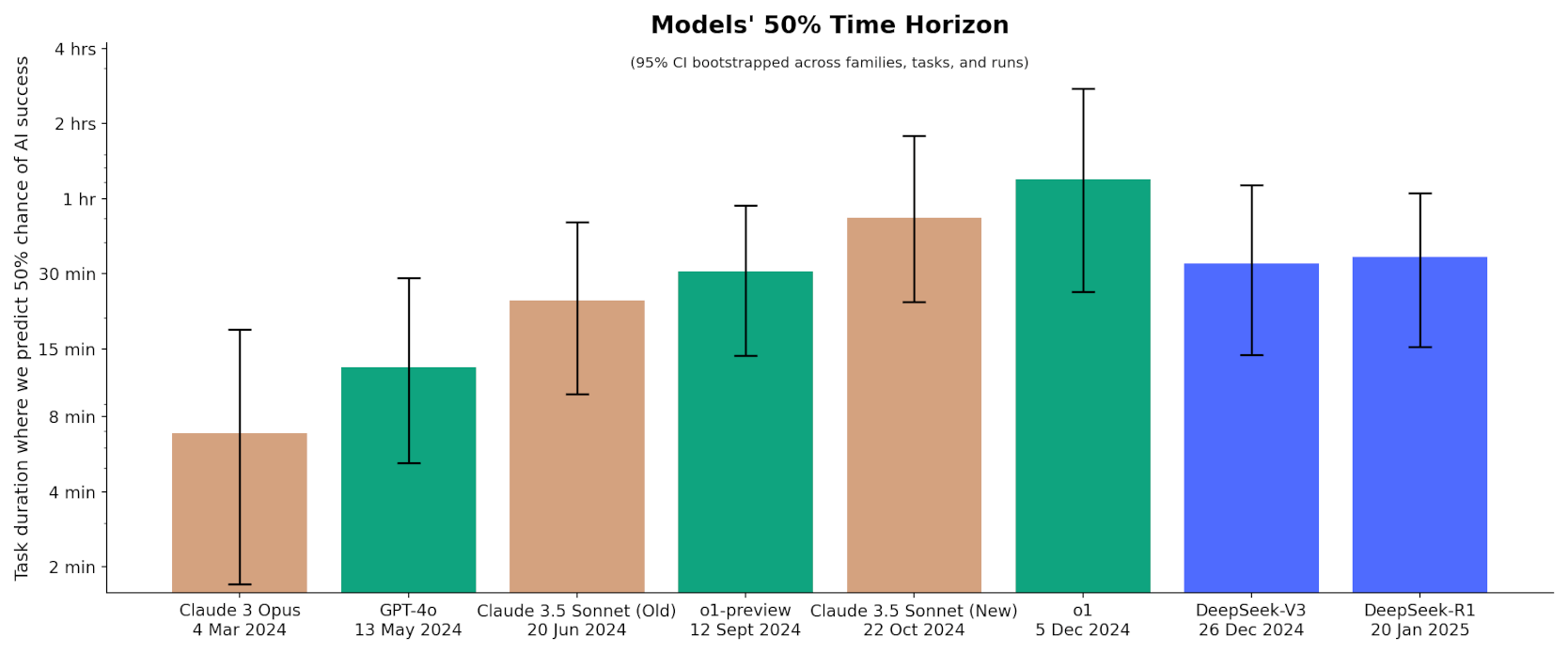
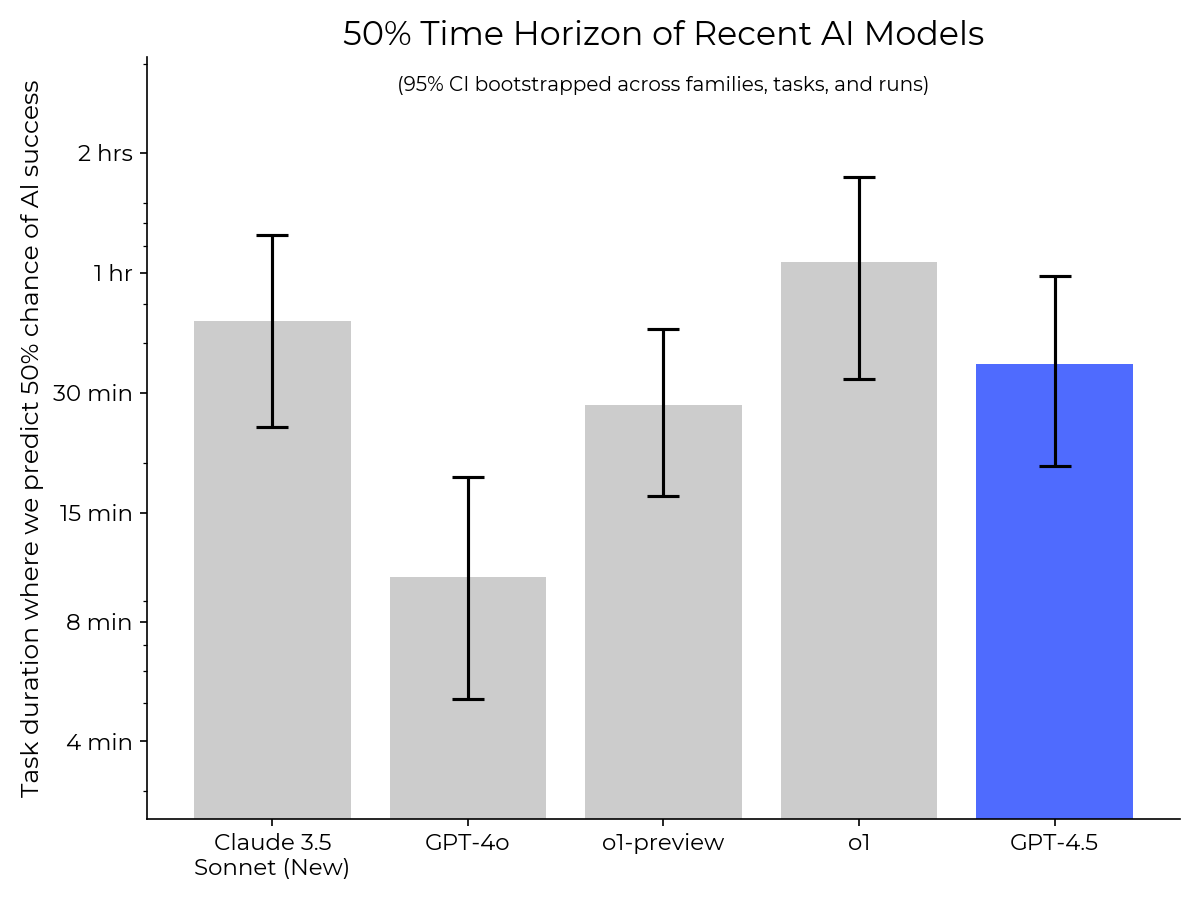
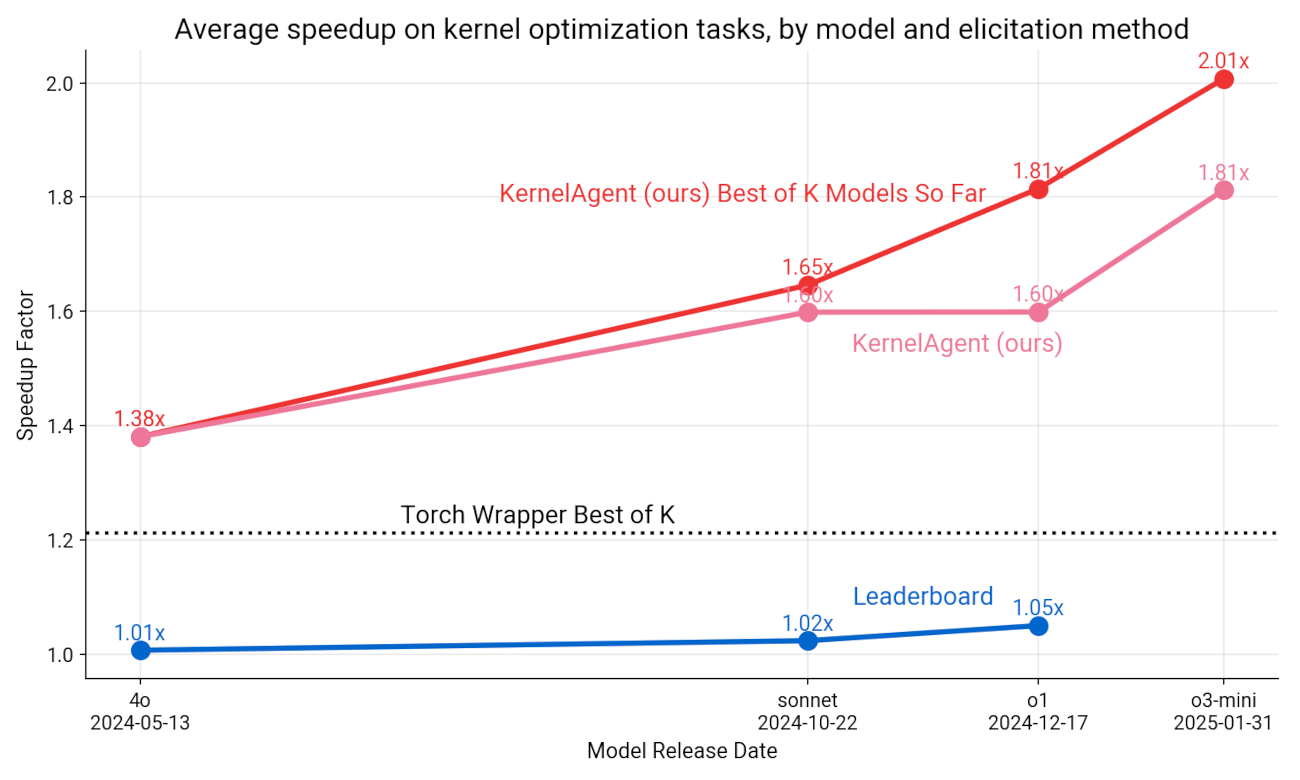
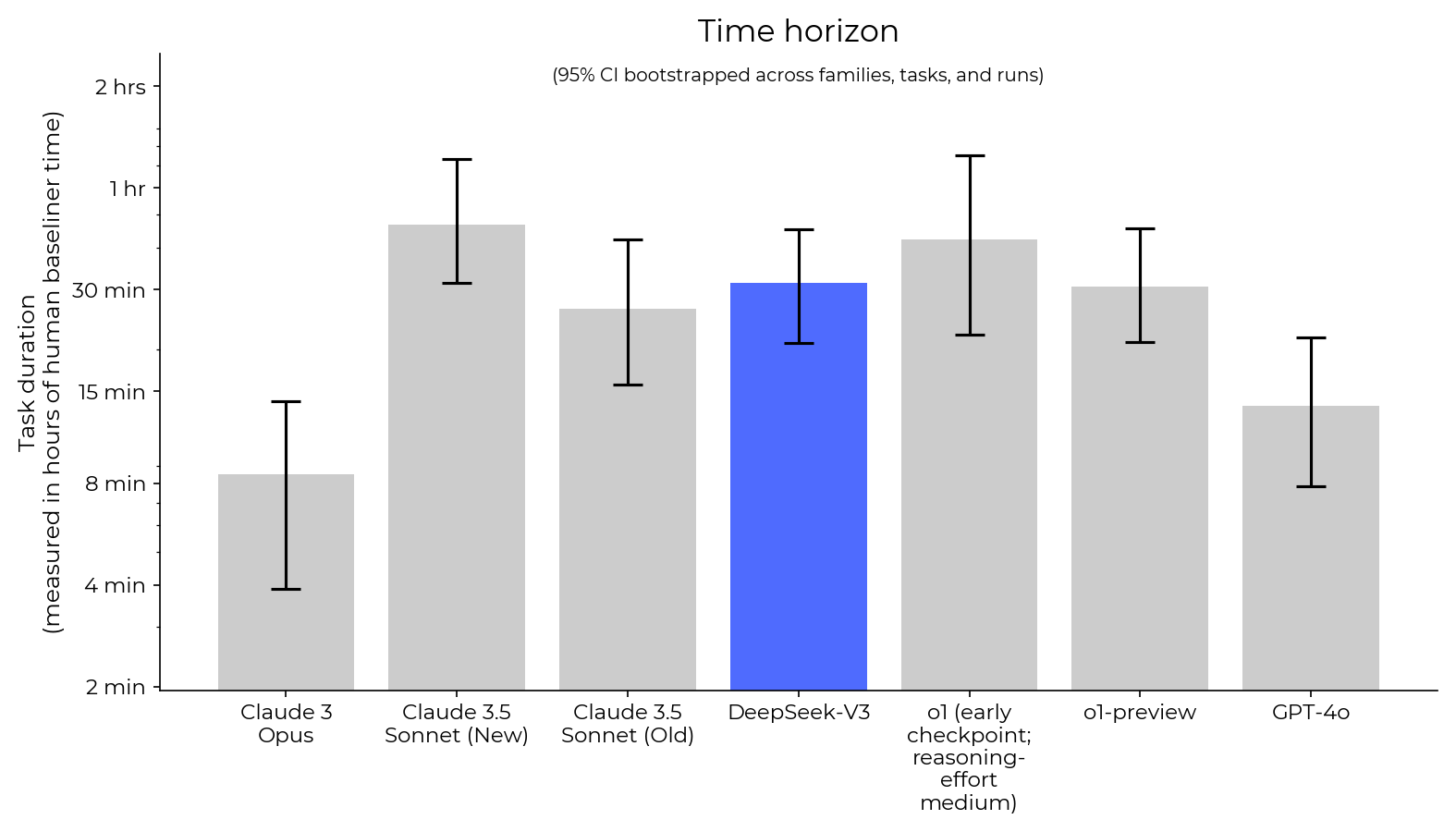
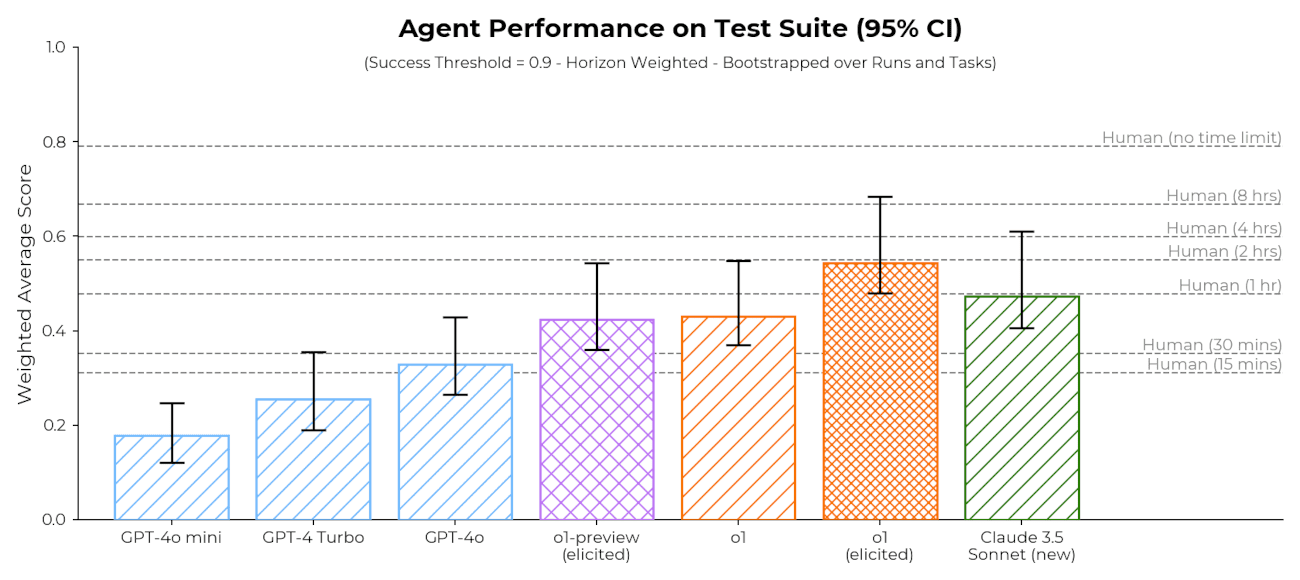
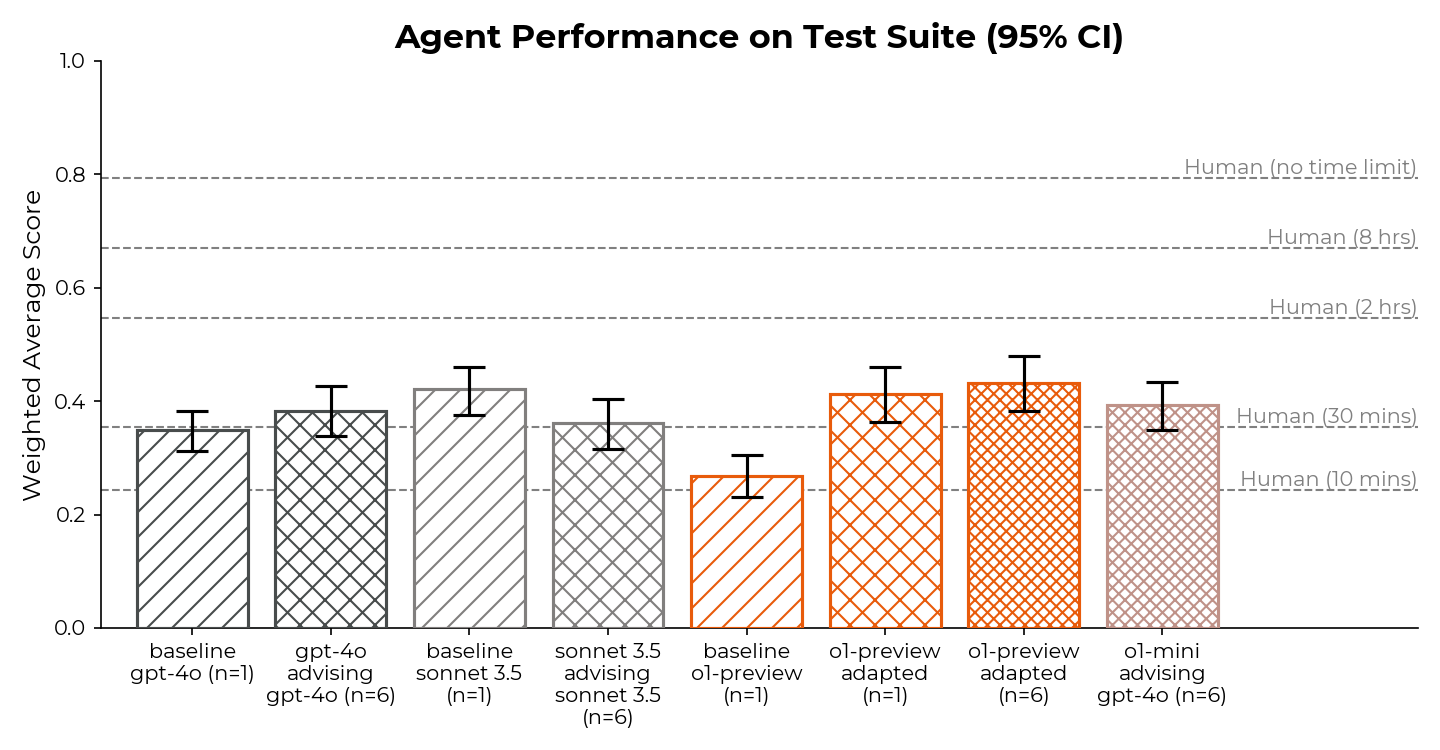
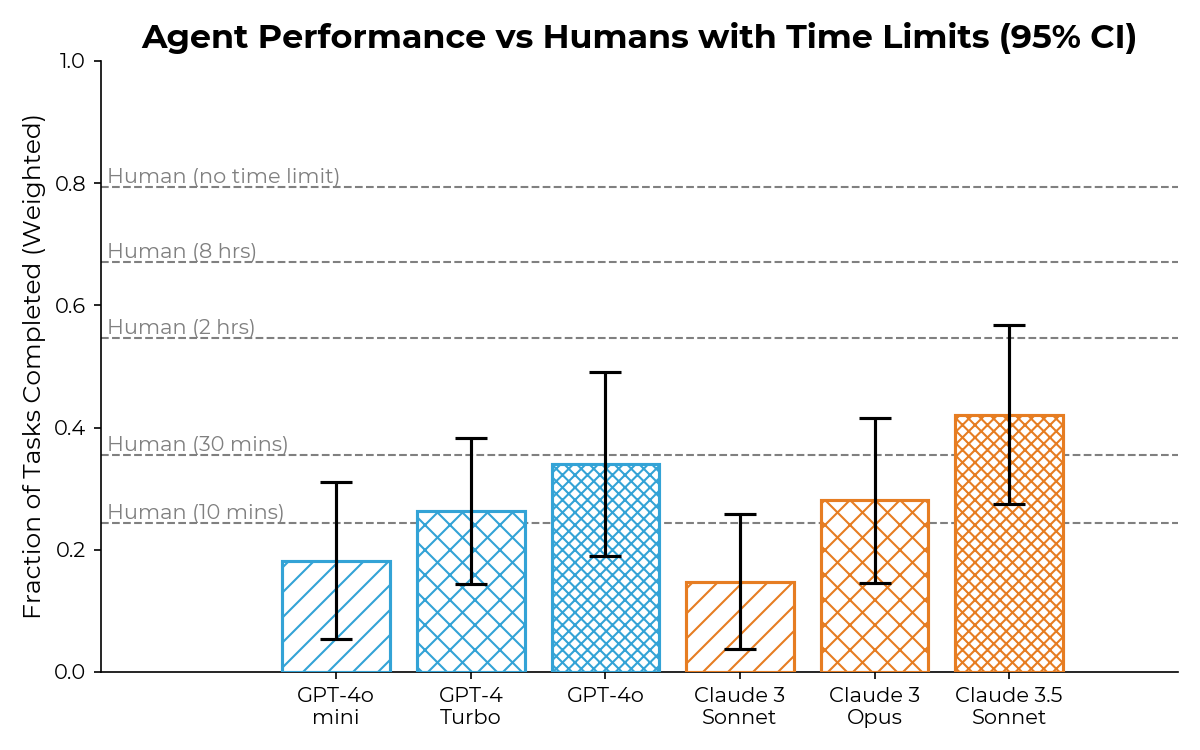
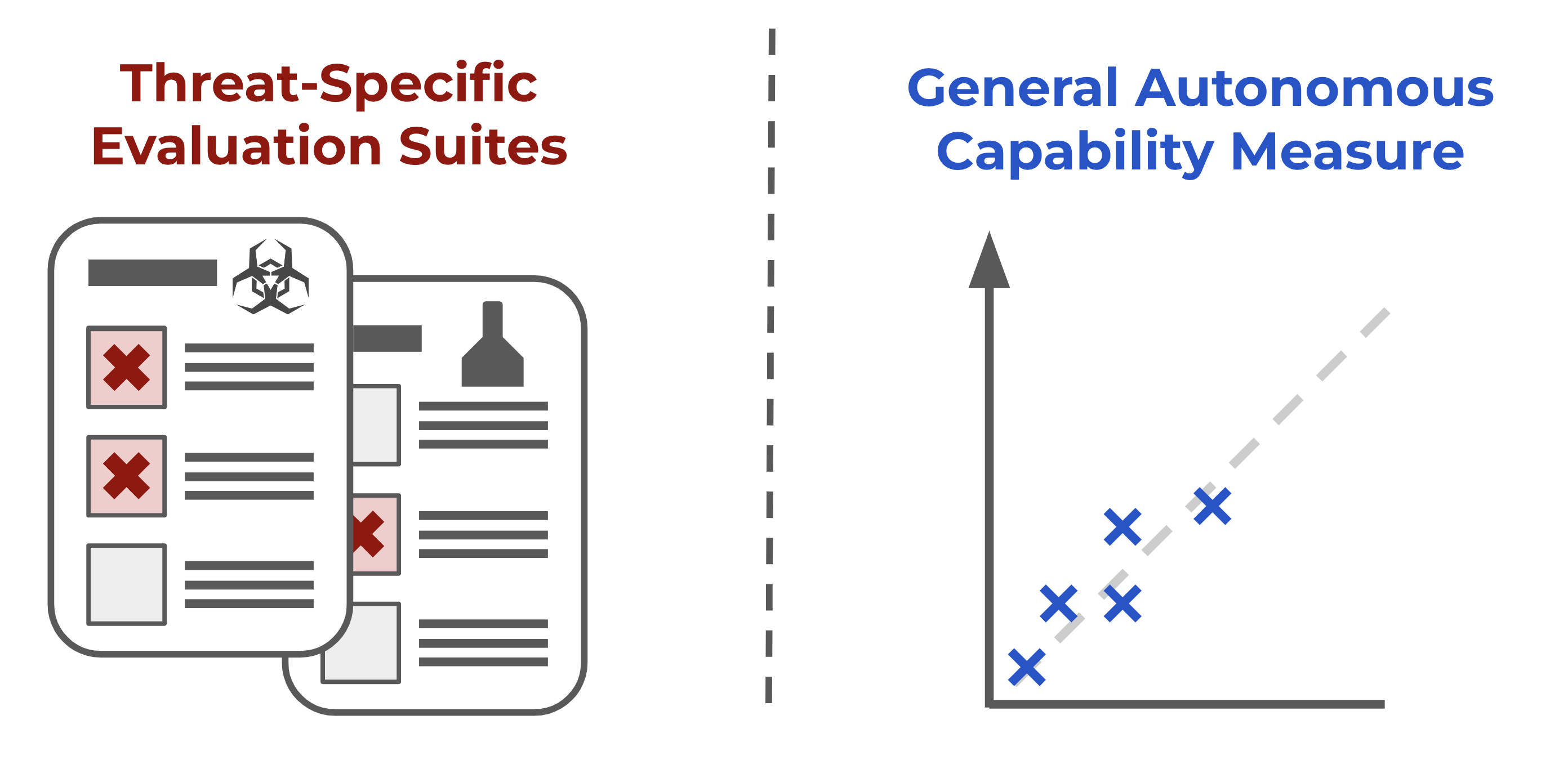
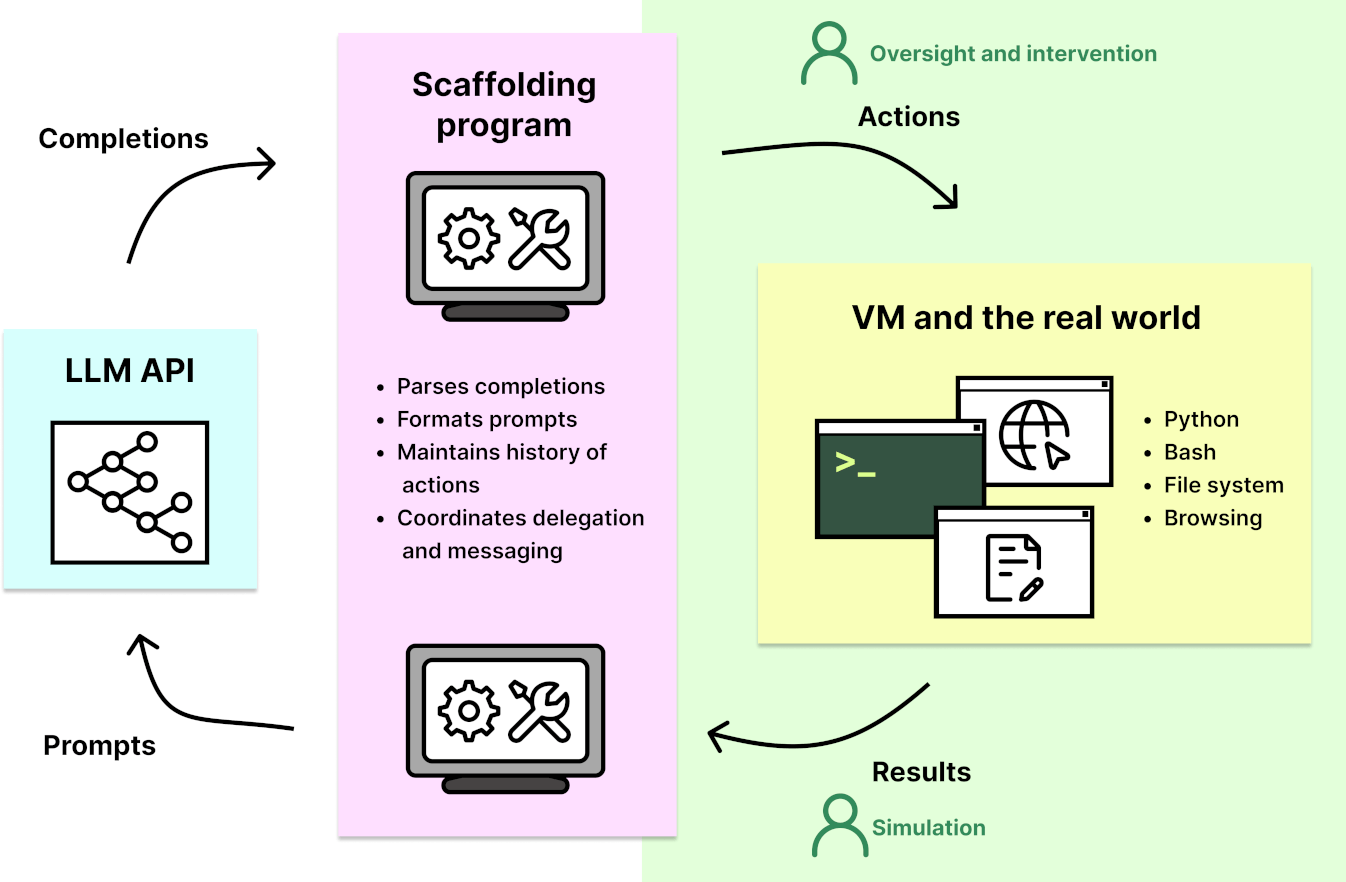
AI agents are improving rapidly at autonomous software development and machine learning tasks, and, if recent trends hold, may match human researchers at challenging months-long research projects in under a decade. Some economic models predict that automation of AI research by AI agents could increase the pace of further progress dramatically, with many years of progress at the current rate being compressed into months. AI developers have identified this as a key capability to monitor and prepare for, since the national security implications and societal impacts of such rapid progress could be enormous.
阅读英文原文