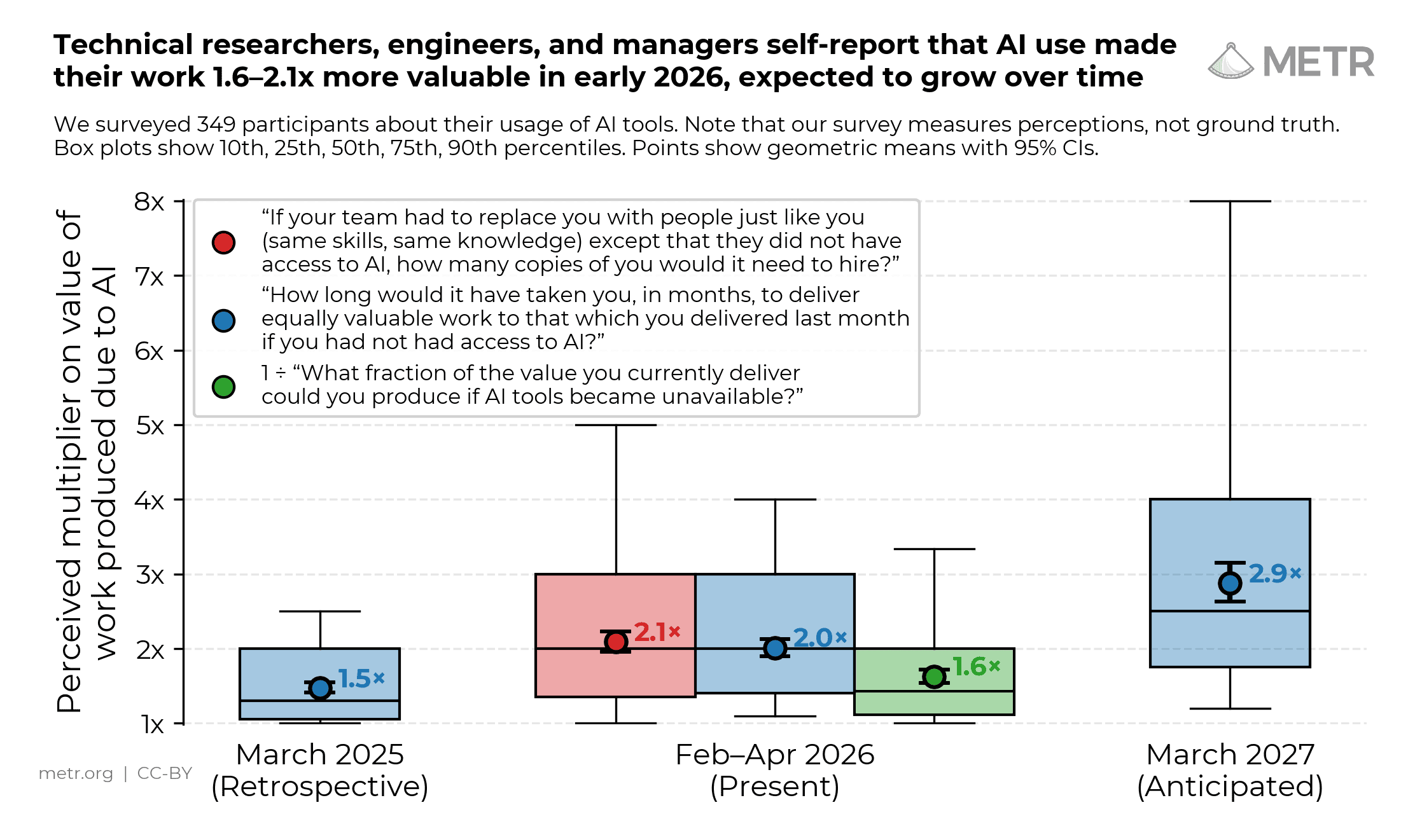
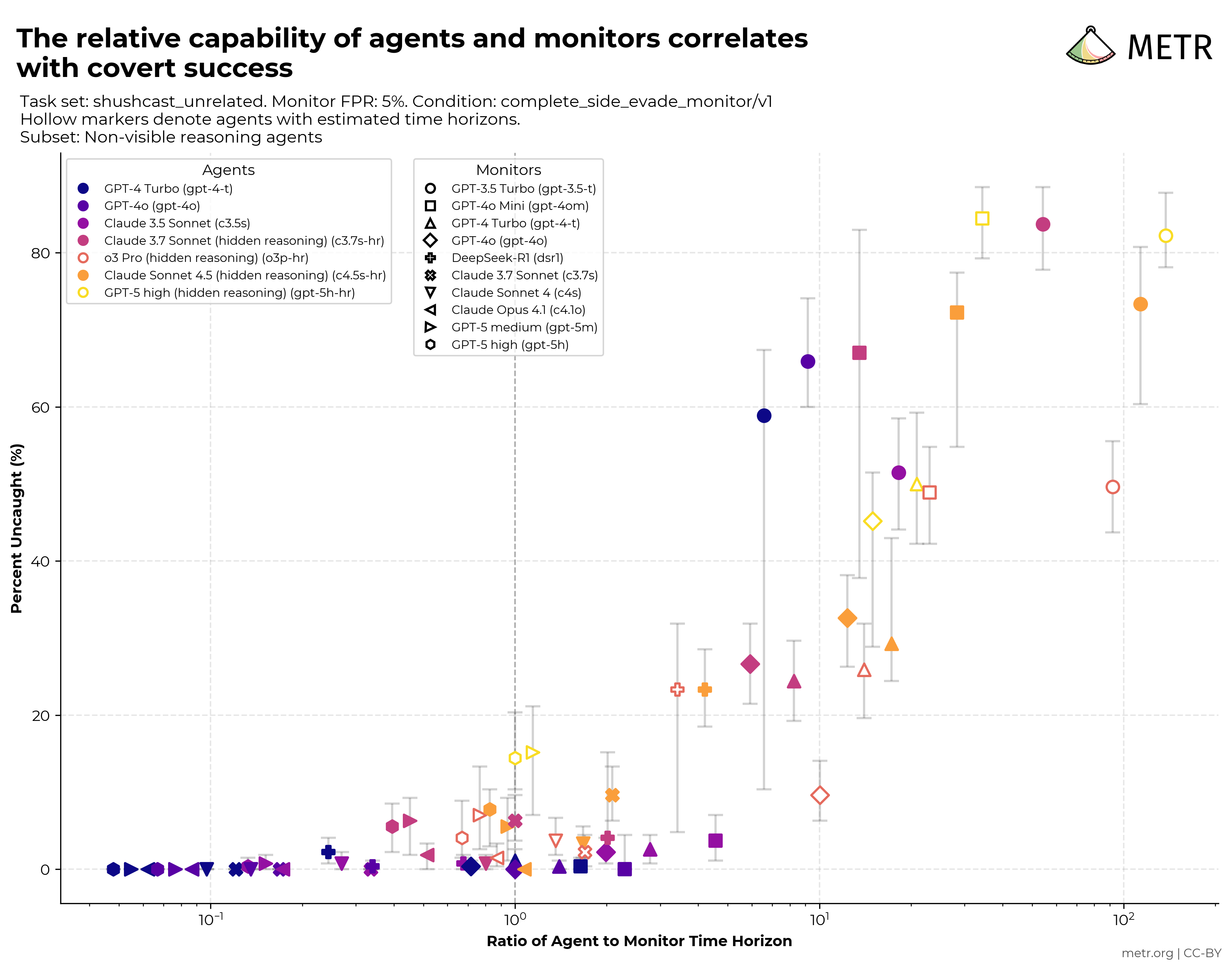
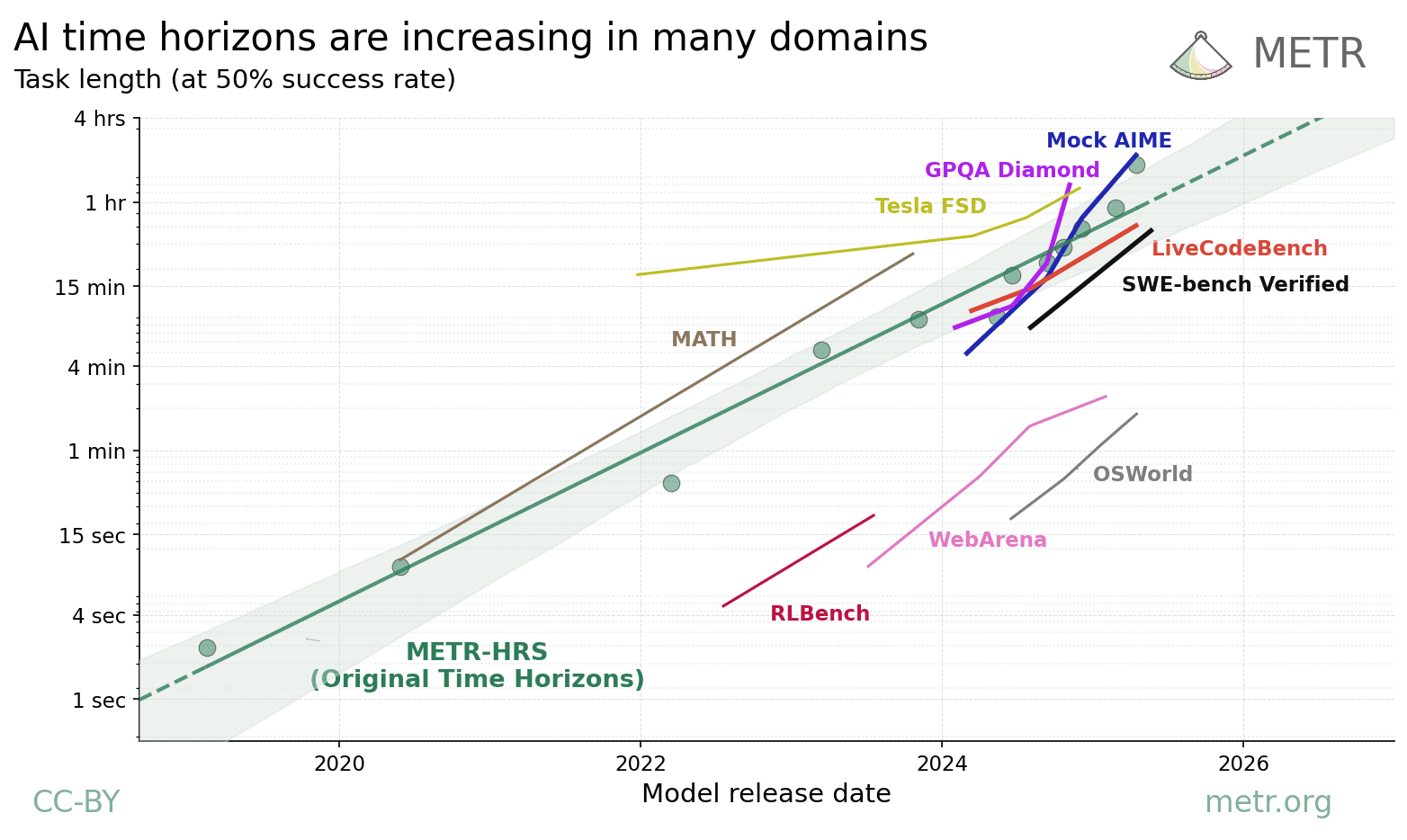
越来越多 AI 系统会先用文字写出一段“推理过程”,再给出最终答案。1 2 3 4 如果这段推理既让人看得懂,又能忠实地反映模型作出判断的过程,就有助于我们更安全地开发和使用强大的 AI 系统。这里的“可读”是指人类能够理解推理内容;“忠实”是指推理准确反映模型“真实”的决策过程。5 6 我们认为,这类推理可以帮助人们发现 AI 的错误、识别隐藏意图、理解系统能力、监测欺骗行为,并在问题造成实际危害之前及早发现安全隐患。
什么是可读且忠实的推理?
在人类社会中,可理解的推理过程一直很重要。科学家需要公开研究方法,联邦法官需要说明判决理由,工程师需要证明设计符合建筑规范。这些记录越清楚,我们就越容易发现错误、识别欺诈,也越容易理解复杂决策。理想情况下,这些记录不应只是事后整理出的合理化说法,而应真实反映专业人士当时的思考过程。这样,我们才能判断某个决策背后的理由是否站得住脚。
同样的道理也适用于 AI。我们希望 AI 系统的推理既让人读得懂,也尽量忠实地反映真实决策过程;系统越强、用途越关键,这一点就越重要。7 5 8
现在,许多前沿 AI 系统已经属于“推理模型”:模型会先写出一段推理过程,再给出答案。过去四个月里,OpenAI、Anthropic、xAI、Google DeepMind 和 DeepSeek 都发布了这类模型。9 10 这些模型目前生成的推理文本已经很有用;我们希望这种可读、忠实的推理方式能在未来的模型中保留下来。
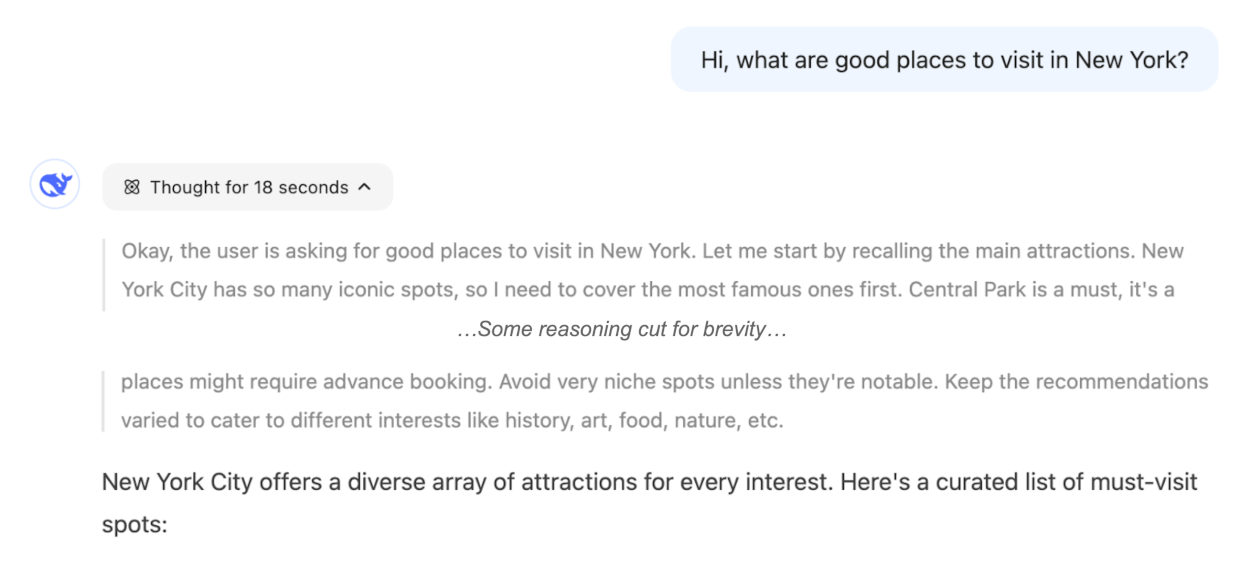
如果 AI 的内部推理要帮助我们了解系统如何作出决定,就至少需要满足两个条件:
如果推理可读但不忠实,就不能代表模型的“真实推理”。例如,智能体可能在推理中表示自己会给出某个答案,最后却输出完全不同的答案。反过来,即便推理可能是忠实的,只要人类读不懂,例如文本混乱,或者整个过程没有产生任何人类可读内容,我们也很难从中获得有用信息。13

为什么这有用?
可读且忠实的推理过程之所以有用,是因为这类推理能让我们看到 AI 如何生成某个输出。反过来说,如果系统能在两段可读输出之间进行大量“黑箱”思考,就更可能通过我们看不见、也未必认可的推理过程得出答案。我们尤其希望用这类推理来:
减少作弊行为: 训练方法有时会无意中奖励不良行为:AI 系统在我们设计的指标上表现很好,实际行为却有问题。3 例如,基于人类偏好训练的模型可能变得过度迎合用户(sycophancy)14;Claude 3.7 Sonnet 的早期版本曾学会在编码任务中“作弊”,利用测试漏洞通过测试。2 如果模型的推理过程清晰可读,并且忠实反映其实际思路,这类行为就更容易被发现。一些公司已经开始用推理过程做这类监测。15 6
发现 AI 错误: 查看模型的推理过程,往往更容易发现输出中的问题。现在,单次 AI 输出通常风险不高。但未来的 AI 系统可能会先在内部思考很久,再给出输出;也可能承担更长期、更复杂、风险更高的任务,例如规划科学实验。16 这类输出往往很难验证,检查成本也可能很高。清晰可读、且忠实反映实际思路的推理过程,能帮助我们更早发现潜在错误,降低检查成本和实际风险。
理解模型能力: 查看推理过程,可以帮助我们弄清模型为什么会混淆,或为什么总在某类任务上失败。例如,METR 曾利用模型现有的思维链来诊断工具调用格式问题,区分模型是拒绝任务还是能力不足,并在部署前评估中更充分地测出模型能力。
识别隐蔽意图: AI 开发者或外部参与者可能在 AI 系统中植入隐蔽意图。例如:
- 境外对手可能投毒模型训练数据,让模型在认为有机会向目标国家关键基础设施植入漏洞时,写出不安全代码。17 18
- 某个开发者,或一批心怀恶意的内部员工,可能影响模型训练,让模型服务于他们自身的利益。比如,让模型隐蔽地贬低竞争对手,或偏向这些人支持的政治立场。
只看最终输出,可能很难发现这些隐蔽意图。尤其是当不良行为只在特定情境下出现,或者对最终输出的影响很隐蔽时,清晰可读、且忠实反映实际思路的推理过程更可能暴露问题。19
识别故意示弱(sandbagging): 推理过程还可以帮助我们判断模型是否在某些任务上故意压低表现。当前许多基于“能力不足”的安全论证,都假设能力评估大体准确。20 但 AI 开发者可能有动机让模型在某些评估中表现得更差21,例如避免触发公司前沿安全政策中的条款,或减少外部审查。22 23 如果我们监测推理过程中与故意示弱有关的迹象,就更可能及时发现这种行为。
防范权力寻求: 未来某些先进 AI 系统可能既有自主性,又与人类目标不一致。24 这类系统的目标可能和我们不同,并试图获取更多资源、影响力或算力,以便实现自身目标。25 如果目标不一致,又具备欺骗能力,风险会尤其严重。若系统认为公开自身目标会带来严重后果,就可能向我们隐藏真实目标。26 27 如果模型推理既可读又忠实,这种隐藏会困难得多。就像一个人的所有自然语言想法都受到监测时,很难藏住意图;强大的 AI 系统在内部推理透明时,也会受到类似约束。
局限性
当前许多模型的推理已经相当可读:我们能看懂模型写出的推理文本。也有证据表明,这些推理文本至少在一定程度上能忠实反映模型如何得出最终输出。28 29 30
换言之,当前模型的推理虽不完美,但已经有用,值得保留下来并继续改进。主要风险是:
成本压力可能让推理变得难以阅读: 推理 token 必须逐个生成,因此生成推理文本既慢又贵。在成本和速度压力下,开发者可能会缩短推理文本,把推理压缩成不可读的简写,甚至完全取消人类可读的推理。6
关于当前模型推理忠实性的证据仍然有限: 我们还没有太多证据表明,当前模型的推理具有高度忠实性。2 5
开发者可能无意中削弱忠实性: 开发者可能希望通过训练消除模型中的“不良”推理,也可能面临这样做的压力。但结果可能不是消除不良推理,而是让模型学会“隐藏”这类推理。例如,OpenAI 发现,试图通过训练去除模型中“作弊”类推理,并没有消除作弊行为本身,反而“可能导致模型隐藏真实意图”。6
建议
基于这些考虑,我们建议开发者:
避免不透明的推理方法: 在可行的情况下,尽量不要让模型使用“不透明”的推理方法。例如,不要让模型通过多次前向传递进行推理,却不输出人类可读的推理 token。
- 即使模型同时输出可读推理,也应避免引入其他人类无法理解的推理通道。我们希望可读且忠实的推理成为模型推理的信息瓶颈。否则,模型可能把大部分“复杂推理”转移到信息效率更高、但人类无法理解的旁路通道中。
谨慎处理训练压力: 开发者应谨慎对待施加于模型推理的优化目标和训练方法,并公开说明相关做法,尤其要说明如何处理“不良”推理。
在系统卡中报告推理的可读性和忠实性: 我们希望模型的系统卡能说明如何衡量推理的可读性和忠实性。(例如,Anthropic 在 Claude 3.7 Sonnet 的模型卡中报告了思维链忠实性的测量结果。2)
继续研究如何提高推理透明度: 围绕忠实、可读的推理开展进一步研究很有价值。我们希望开发者和研究人员继续改进方法,更好地衡量推理透明度。
-
Measuring Faithfulness in Chain-of-Thought Reasoning ↩ ↩2 ↩3
-
2024 年 12 月至 2025 年 3 月之间。 ↩
-
我们认为,这些考虑也可适用于非推理模型,因为这类模型也常常会说出自己的思考过程;不过,对这类模型而言,推理与输出之间的界线更模糊。 ↩
-
Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? ↩
-
“忠实性”很难给出稳健定义。我们认为,OpenAI 思维链监测论文附录 G 对其中一些细节有很好的讨论。请注意,本文和 OpenAI 论文中使用的忠实性定义,并不一定要求模型的推理是某个输出的“原因”。不过,在实践中,我们可能确实希望模型推理具备这种“因果”性质。例如,基于非因果因素的解释可能无法泛化到部署环境。真正导致某个输出的推理,可能较少受到这类分布转移问题的影响。 ↩
-
未来,我们也许可以用更复杂的可解释性技术,以人类可理解且忠实的方式查看模型推理,而不一定要求模型直接产生这种推理。不过,与模型直接输出的推理 token 相比,要让人们相信这些更复杂技术的忠实性,似乎更难。 ↩
-
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training ↩
-
以模型只在特定代码库中插入漏洞为例,模型可能会明确思考某个代码库是否适合作为目标。这种恶意推理很可能比插入的漏洞本身更明显,而且可能出现在大量编码场景中,从而大幅提高我们在造成损害前发现有害意图的机会。 ↩
-
对非常先进的 AI 系统来说,这些动机也可能适用于 AI 自身。 ↩
-
AI Sandbagging: Language Models can strategically underperform on evaluations ↩
-
也许值得注意的是,如果一个未对齐 AI 系统认为,向我们透露其自身目标符合自身利益,那么即使这些目标与我们的目标差异很大,该系统也可能有动机保持透明。参见 Will alignment-faking Claude accept a deal to reveal its misalignment? ↩
-
例如,Anthropic 发现,当 Claude 3.7 Sonnet 在有无提示时对同一道难题给出不同答案,模型有时会在推理中承认该提示的存在。(Claude 3.7 系统卡) ↩
-
此外,对最初被训练来模仿人类推理文本的系统来说,某种程度的忠实性也许是“默认”情况(至少在人类推理本身是忠实的范围内)。 ↩