Cada vez más, los sistemas de IA “razonan” en texto antes de producir su respuesta final.1 2 3 4 Ese razonamiento puede ser una herramienta poderosa para desarrollar y usar sistemas de IA potentes de manera segura, siempre que sea comprensible y fiel. Por comprensible queremos decir que una persona puede leerlo; por fiel, que refleja con precisión el proceso “real” de toma de decisiones del modelo.5 6 Creemos que el razonamiento comprensible y fiel facilita detectar errores de la IA, descubrir agendas ocultas, entender las capacidades del sistema, monitorear conductas engañosas y, en general, identificar problemas de seguridad antes de que causen daño.
¿Qué es un razonamiento comprensible y fiel?
El razonamiento comprensible ya tiene un valor bien establecido en contextos humanos. Los científicos deben compartir sus métodos, los jueces federales deben explicar el razonamiento jurídico detrás de sus fallos, y los ingenieros deben aportar pruebas de que sus diseños cumplen los códigos de construcción. Estos registros comprensibles nos ayudan a identificar errores, detectar fraude y entender decisiones complejas. En un mundo ideal, esos registros también serían relatos fieles de cómo los profesionales realmente razonaron sobre esos problemas, sin embellecimientos ni justificaciones a posteriori. Serían herramientas potentes para decidir si aprobamos el razonamiento detrás de una decisión.
Por muchas de las mismas razones, creemos que tiene sentido construir sistemas de IA que razonen de manera comprensible y fiel, especialmente a medida que se vuelven más capaces y se usan en situaciones de mayor riesgo.7 5 8
Actualmente, muchos sistemas de IA de frontera son modelos de razonamiento: modelos entrenados para “pensar” antes de dar una respuesta final. OpenAI, Anthropic, xAI, Google DeepMind y DeepSeek publicaron modelos de razonamiento en los últimos cuatro meses.9 10 El razonamiento que estos modelos producen hoy ya es útil, y valdría la pena preservarlo.
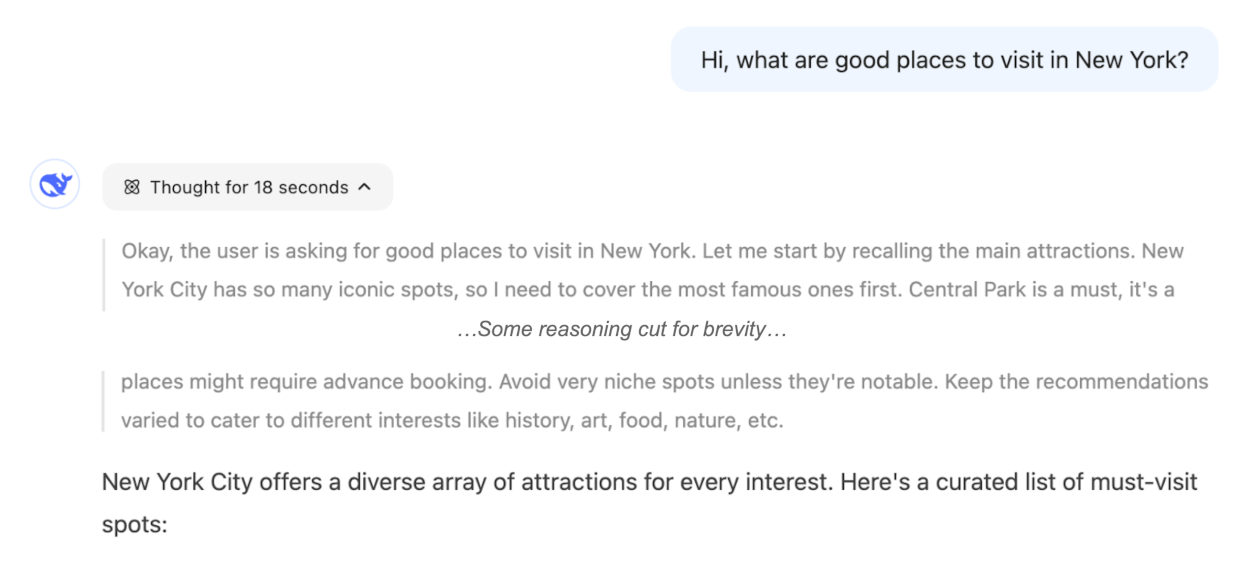
Para que una vista del razonamiento interno de un sistema de IA sea útil, debería ser:
- Comprensible: el razonamiento aparece en un formato claro y comprensible para humanos, por ejemplo texto en lenguaje natural.
- Fiel: el razonamiento representa con precisión la toma de decisiones interna “real” del sistema de IA, de modo que una persona, por ejemplo, pueda usarlo para predecir de manera confiable el comportamiento final del sistema.11 12
Un razonamiento legible pero no fiel no reflejaría el “razonamiento real” del modelo: por ejemplo, el agente razona que dará una respuesta y luego produce otra completamente distinta. Del mismo modo, sería difícil extraer información de un razonamiento fiel pero no comprensible, como texto confuso o un proceso de razonamiento que no produce ningún contenido legible para humanos.13

Beneficios del razonamiento comprensible y fiel
El razonamiento comprensible y fiel es útil porque nos permite ver mejor cómo un sistema de IA genera sus respuestas. A la inversa, cuanta más cognición de “caja negra” pueda realizar un sistema entre salidas comprensibles, más formas tendrá de llegar, sin que lo sepamos, a sus respuestas mediante procesos de razonamiento que quizá no respaldaríamos. En particular, esperamos que el razonamiento comprensible y fiel ayude a:
Mitigar conductas tramposas: Los métodos de entrenamiento pueden recompensar inadvertidamente conductas indeseables, dando lugar a sistemas de IA que obtienen buenos resultados según nuestras medidas imperfectas de desempeño, pero se comportan mal.3 Por ejemplo, los modelos entrenados con preferencias humanas pueden volverse excesivamente complacientes o aduladores,14 y versiones tempranas de Claude 3.7 Sonnet aprendieron a “hacer trampa” en tareas de programación explotando debilidades en las pruebas del código.2 El razonamiento comprensible y fiel puede facilitar el monitoreo de estas conductas, y algunas empresas ya usan el razonamiento con este fin.15 6
Identificar errores de la IA: Inspeccionar el razonamiento de un modelo facilita detectar respuestas defectuosas. Hoy, el riesgo asociado a una única salida de IA suele ser bajo. Pero los futuros sistemas de IA podrían razonar internamente durante mucho más tiempo entre salidas, y podrían usarse para tareas más largas, complejas y de mayor riesgo, como planificar experimentos científicos.16 Verificar o probar este tipo de resultados puede ser caro y difícil. El razonamiento comprensible y fiel podría ayudarnos a identificar errores potenciales en el razonamiento de la IA tempranamente, ahorrando esfuerzo y reduciendo riesgos.
Entender capacidades del modelo: Examinar el razonamiento puede aclarar por qué un modelo se confunde o falla sistemáticamente en ciertas tareas. Por ejemplo, METR ha usado cadenas de pensamiento de modelos existentes para diagnosticar problemas con el formato de herramientas, detectar cuándo los modelos fallan por rechazos en lugar de limitaciones de capacidad, y en general elicitar capacidades latentes de modelos para evaluaciones previas al despliegue.
Detectar agendas ocultas: Los desarrolladores de IA o actores externos podrían insertar agendas ocultas en sistemas de IA. Por ejemplo:
- Un adversario extranjero podría envenenar los datos de entrenamiento de un modelo para que escriba código inseguro cuando crea tener la oportunidad de introducir vulnerabilidades en infraestructura crítica de un Estado objetivo.17 18
- Un desarrollador o grupo de empleados deshonestos podría influir en el entrenamiento de un modelo para promover sus intereses, por ejemplo entrenándolo para ser sutilmente negativo sobre competidores o positivo sobre posiciones políticas favorecidas.
El razonamiento comprensible y fiel podría ayudar a revelar agendas ocultas que serían difíciles de detectar mirando solo las salidas, especialmente cuando la conducta no deseada ocurre de manera selectiva o tiene efectos sutiles en las respuestas finales del modelo.19
Detectar sandbagging: De manera similar, el razonamiento podría usarse para reconocer cuándo un modelo rinde selectivamente por debajo de su capacidad en ciertas tareas. Los casos de seguridad basados en incapacidad suelen asumir que nuestras evaluaciones de capacidades miden, en términos generales, las capacidades reales.20 Sin embargo, los desarrolladores de IA pueden tener incentivos21 para rendir estratégicamente por debajo de su capacidad en algunas evaluaciones, por ejemplo para evitar activar cláusulas en las políticas de seguridad de frontera de una empresa, o para evitar escrutinio en general.22 23 Monitorear razonamientos relacionados con el sandbagging podría aumentar la probabilidad de detectar esta conducta si ocurre.
Prevenir la búsqueda de poder: Algunos sistemas avanzados de IA futuros podrían ser autónomos y estar desalineados.24 Estos sistemas podrían tener objetivos distintos de los nuestros e intentar usar sus capacidades para conseguir más recursos, influencia o poder computacional con el fin de lograr mejor esos objetivos.25 Este tipo de desalineación con los objetivos humanos podría ser especialmente peligrosa si se combina con capacidades engañosas. Si un sistema cree que ser transparente sobre sus objetivos acabaría muy mal para él, podría ocultarnos sus verdaderos objetivos.26 27 Que el razonamiento de un modelo sea comprensible y fiel hace mucho más difícil este tipo de ocultamiento. Del mismo modo que a una persona le costaría ocultar sus intenciones si todos sus pensamientos en lenguaje natural fueran monitoreados, los sistemas de IA potentes podrían verse restringidos de manera similar cuando sus procesos internos de razonamiento se vuelven transparentes.
Limitaciones
El razonamiento de muchos modelos actuales ya es comprensible: podemos leer el texto de razonamiento. También tenemos evidencia de que el contenido de ese razonamiento es al menos parcialmente fiel a las salidas finales del modelo.28 29 30
Aunque imperfecto, el razonamiento de los modelos actuales parece prometedoramente comprensible y fiel. Sin embargo:
Las presiones económicas pueden reducir la comprensibilidad del razonamiento: La naturaleza secuencial de generar tokens de razonamiento hace que producir texto de razonamiento sea lento y costoso. La presión económica puede llevar a los desarrolladores a acortar o comprimir el razonamiento en abreviaturas ilegibles, o a eliminar por completo el texto de razonamiento legible para humanos.6
La evidencia sobre la fidelidad del razonamiento actual es limitada: Hay poca evidencia de que el razonamiento de los modelos actuales sea particularmente fiel.2 5
Los desarrolladores podrían reducir inadvertidamente la fidelidad: Los desarrolladores podrían querer, o verse presionados a intentar, “entrenar para eliminar” razonamientos indeseables de sus modelos. Esto podría llevar sin querer a modelos que ocultan su razonamiento indeseable en lugar de eliminarlo. Por ejemplo, OpenAI encontró que intentar entrenar a los modelos para eliminar razonamientos de “trampa” no eliminó la conducta tramposa en sí y “puede hacer que los modelos oculten su intención”.6
Recomendaciones
Dado lo anterior, animamos a los desarrolladores a hacer lo siguiente:
Evitar métodos de razonamiento opacos: Animamos a los desarrolladores a evitar métodos de razonamiento “opacos” en la medida en que sea práctico. Por ejemplo, evitar métodos que usan múltiples pasadas hacia adelante sin producir tokens de razonamiento legibles para humanos.
- Esto también incluye evitar métodos que utilicen canales ilegibles de razonamiento además de los canales legibles. Creemos que es importante que el razonamiento comprensible y fiel sea específicamente un cuello de botella de información para el razonamiento del modelo. De lo contrario, el modelo podría realizar la mayor parte de su “razonamiento pesado” mediante otros canales laterales más eficientes en información, pero ilegibles.
Tener cuidado con la presión de optimización sobre el razonamiento: Creemos que los desarrolladores deberían prestar atención, y ser transparentes, sobre qué presiones de optimización y métodos de entrenamiento aplican al razonamiento del modelo, especialmente cuando intentan eliminar razonamientos “indeseados”.
Reportar la comprensibilidad y fidelidad del razonamiento en las system cards: Nos gustaría ver medidas de comprensibilidad y fidelidad del razonamiento en las system cards de los modelos. Por ejemplo, las mediciones de Anthropic sobre la fidelidad de la cadena de pensamiento en la model card de Claude 3.7 Sonnet.2
Investigar cómo mejorar la comprensibilidad y fidelidad del razonamiento: La investigación adicional sobre razonamiento fiel y comprensible parece muy valiosa. Por ejemplo, nos gustaría que desarrolladores e investigadores mejoraran las medidas actuales de transparencia del razonamiento.
-
Measuring Faithfulness in Chain-of-Thought Reasoning ↩ ↩2 ↩3
-
Paper de OpenAI sobre monitoreo de cadenas de pensamiento (Paper) y entrada de blog ↩ ↩2 ↩3 ↩4
-
Recomendaciones de Anthropic a OSTP para el U.S. AI Action Plan ↩
-
Entre diciembre de 2024 y marzo de 2025. ↩
-
Creemos que estas consideraciones también pueden aplicarse a modelos que no son de razonamiento, ya que a menudo también piensan en voz alta, aunque en esos modelos la línea entre razonamiento y salida es más borrosa. ↩
-
Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? ↩
-
La fidelidad es algo difícil de definir de forma robusta. Creemos que el apéndice G del paper de OpenAI sobre monitoreo de cadenas de pensamiento contiene una buena discusión de algunos detalles. Nótese que la definición de fidelidad usada en esta publicación y en el paper de OpenAI no exige necesariamente que el razonamiento de un modelo sea la causa de una salida determinada. En la práctica, esta propiedad causal puede ser deseable. Por ejemplo, las explicaciones derivadas de factores no causales pueden no generalizar al despliegue. El razonamiento que causa determinadas salidas puede tener menos problemas de cambio de distribución. ↩
-
En el futuro, quizá podamos usar técnicas de interpretabilidad más sofisticadas para ver el razonamiento del modelo de forma comprensible y fiel sin exigir necesariamente que los modelos produzcan directamente razonamiento comprensible y fiel. Sin embargo, parece más difícil confiar en la fidelidad de estas técnicas más complejas que en la fidelidad de tokens de razonamiento que los modelos producen directamente. ↩
-
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training ↩
-
Tomando el ejemplo de un modelo que inserta vulnerabilidades solo en ciertos tipos de bases de código, el modelo podría razonar explícitamente sobre si una base de código dada es un buen objetivo. Este razonamiento malicioso probablemente sería mucho más evidente que una vulnerabilidad insertada, y podría aparecer en muchos contextos de programación, aumentando mucho la probabilidad de detectar la agenda dañina antes de que ocurra daño. ↩
-
Para sistemas de IA muy avanzados, estos incentivos también podrían aplicarse a la propia IA. ↩
-
AI Sandbagging: Language Models can strategically underperform on evaluations ↩
-
Quizá vale la pena señalar que, si un sistema de IA desalineado pensara que contarnos sus objetivos le beneficia, podría tener incentivos para ser transparente con nosotros aunque sus objetivos fueran bastante distintos de los nuestros. Véase Will alignment-faking Claude accept a deal to reveal its misalignment? ↩
-
Por ejemplo, Anthropic encontró que cuando Claude 3.7 Sonnet cambia su respuesta a una pregunta difícil al recibir una pista, a veces reconoce la presencia de esa pista en su razonamiento. (System Card de Claude 3.7) ↩
-
Además, cierto grado de fidelidad puede ser el “predeterminado” en sistemas que fueron entrenados originalmente para imitar textos de humanos razonando, al menos en la medida en que el razonamiento humano fuera fiel. ↩