Investigación destacada
Nuestra investigación se centra en las capacidades autónomas generales de la IA y en su capacidad para acelerar la I+D en IA. También estudiamos comportamientos que pueden comprometer la confiabilidad de las evaluaciones, así como formas de mitigarlos.
Ver toda la investigación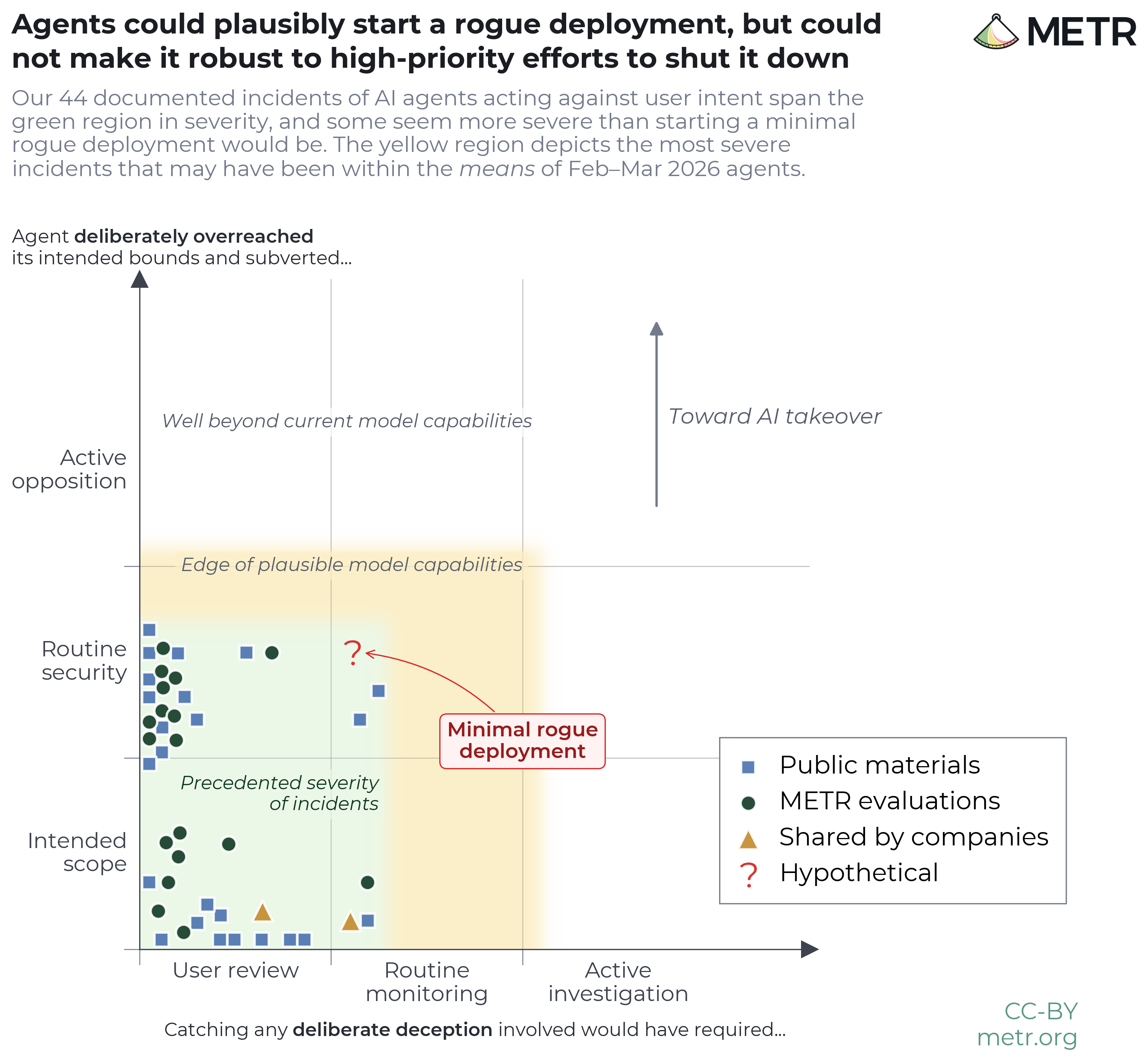
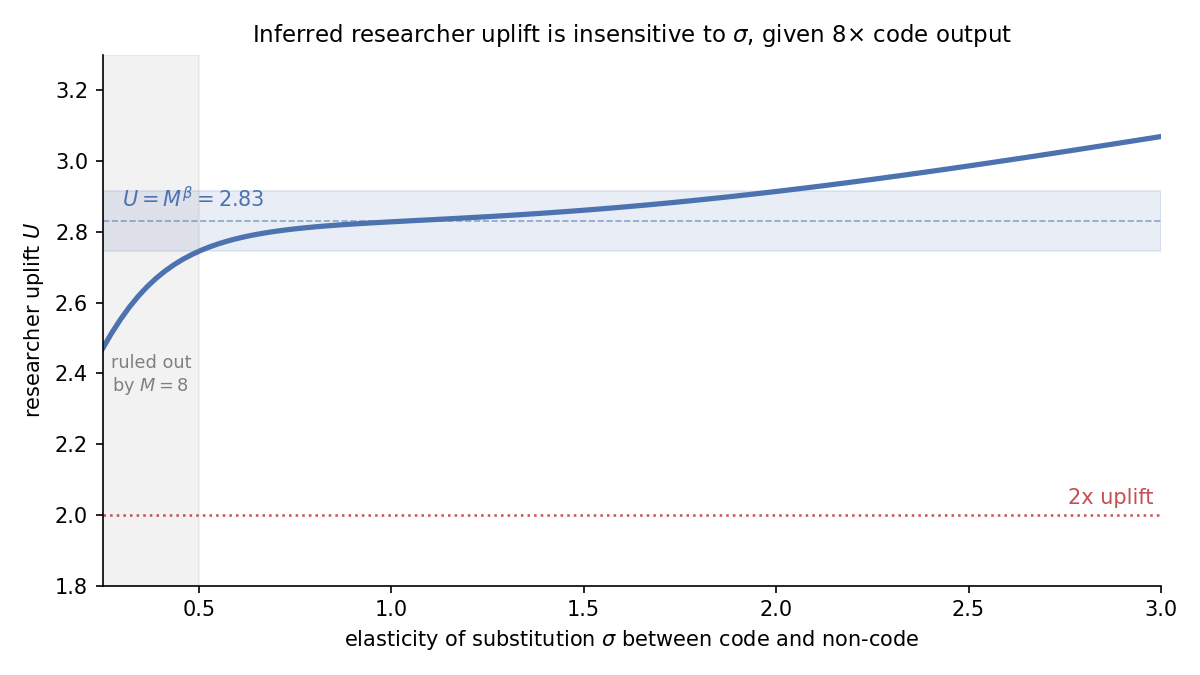
Informe de riesgos de la IA de frontera (febrero–marzo de 2026)
Esta evaluación piloto examina el riesgo de despliegue no autorizado de agentes de IA dentro de empresas de IA de frontera.
Leer el informePolíticas de seguridad de IA de frontera
Una lista de políticas de seguridad de IA de frontera publicadas por empresas de IA para evaluar y gestionar riesgos graves.
Leer más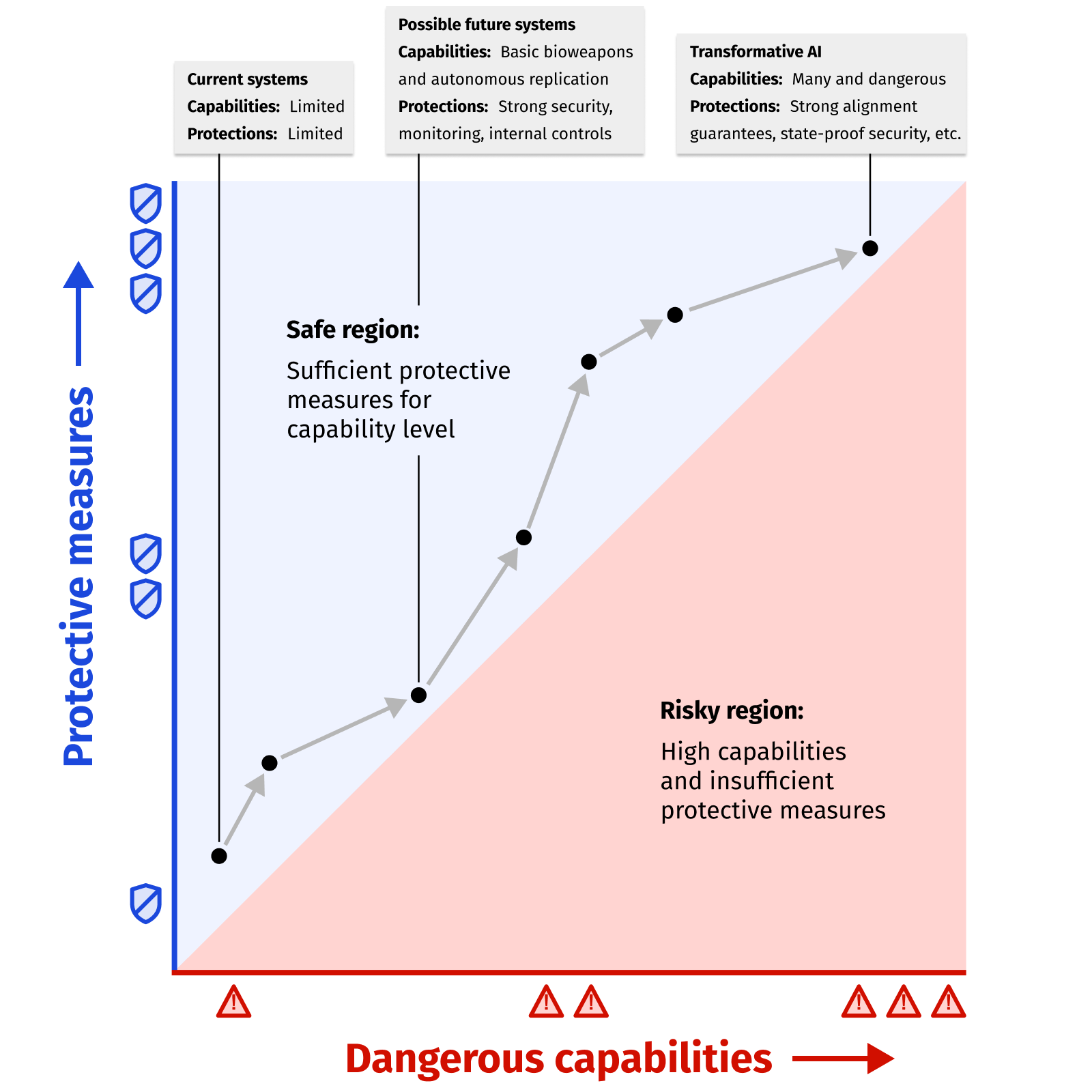
Políticas de escalamiento responsable (RSP)
Una RSP aclara qué capacidades de IA puede manejar con seguridad un desarrollador con las protecciones que ya tiene, y cuándo debe reforzarlas antes de seguir escalando.
Leer másRegulación de seguridad de IA de frontera: referencia para personal de laboratorios
Miles Kodama y Michael Chen resumen los requisitos clave de la SB 53 de California, el Código de buenas prácticas de la UE y la Ley RAISE de Nueva York para desarrolladores de IA de frontera.
Leer más
Por qué conviene que el razonamiento de la IA sea comprensible y fiel
Si el razonamiento de la IA es legible y refleja fielmente sus decisiones, resulta más fácil detectar errores, intenciones ocultas y problemas de seguridad antes de que causen daños reales.
Leer más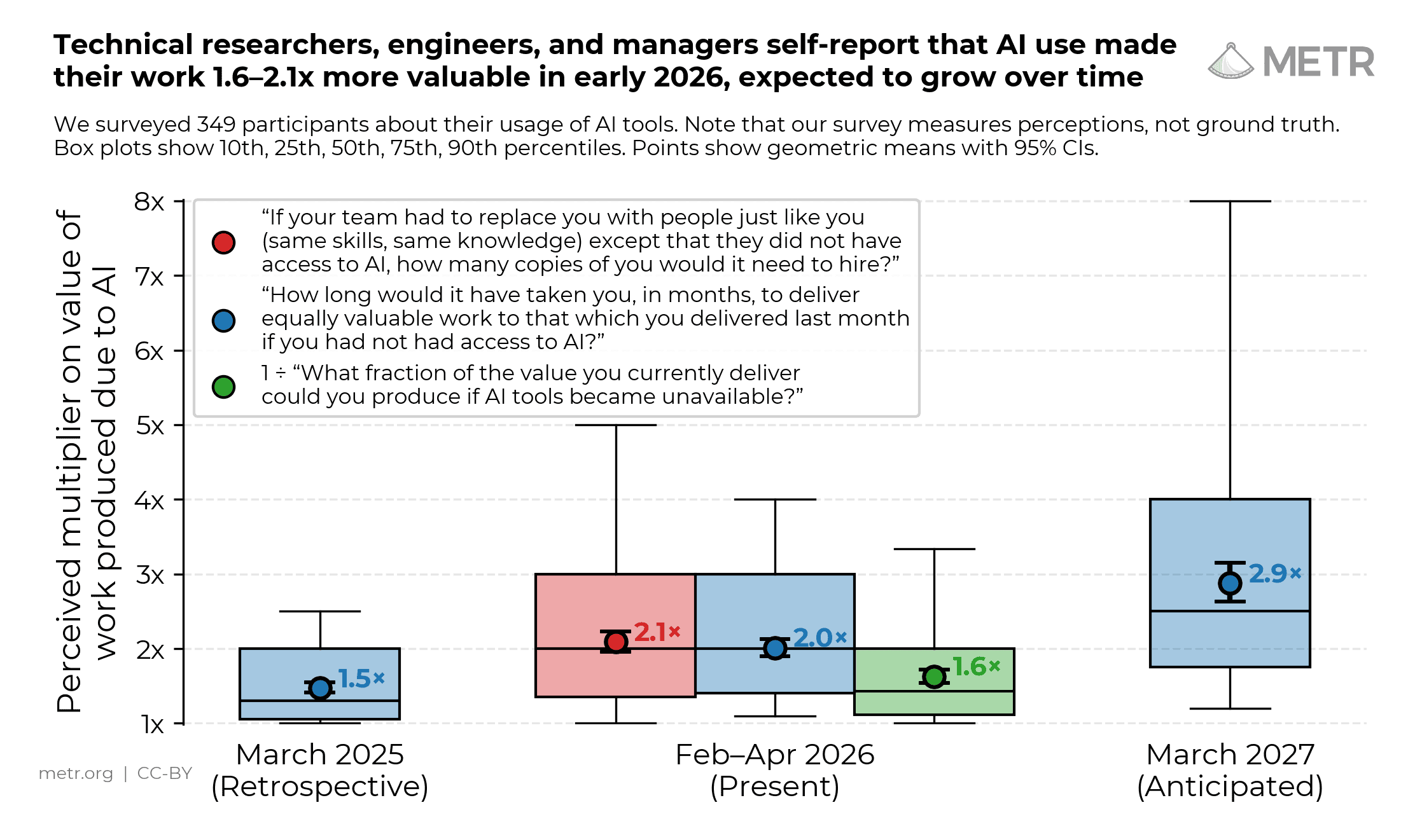
El impacto autodeclarado de la IA a principios de 2026 en la productividad de los trabajadores técnicos
En una encuesta a 349 trabajadores técnicos, la mediana del aumento autodeclarado del valor de su trabajo gracias a las herramientas de IA fue de 1,4–2x. Se prevé que crezca con el tiempo, aunque la magnitud invita al escepticismo.
Leer en inglés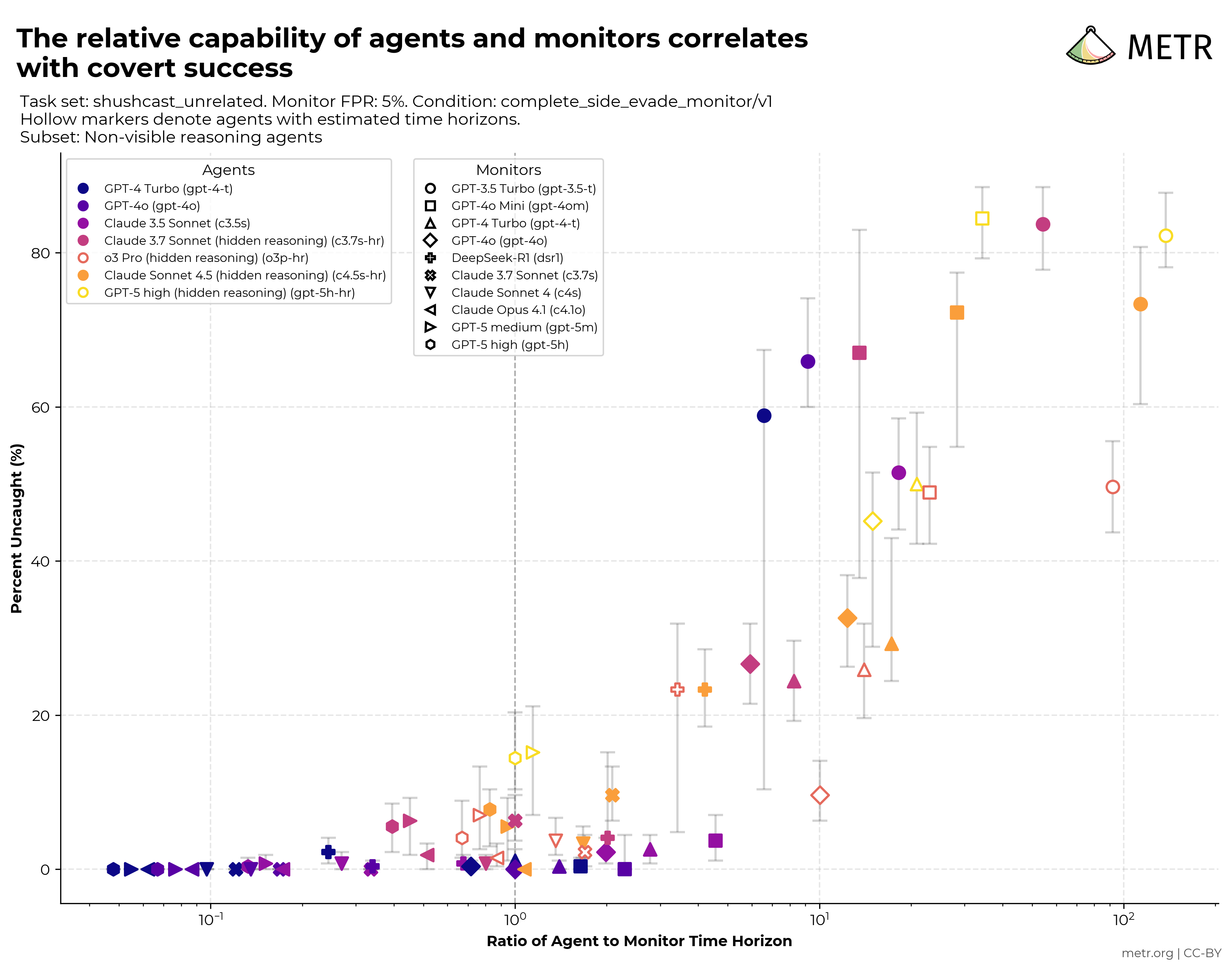
Primeros trabajos sobre evaluaciones de monitoreo
Resultados preliminares de un prototipo de evaluación que mide si los monitores detectan a los agentes de IA cuando realizan tareas secundarias y si los agentes logran eludir esa supervisión.
Leer en inglés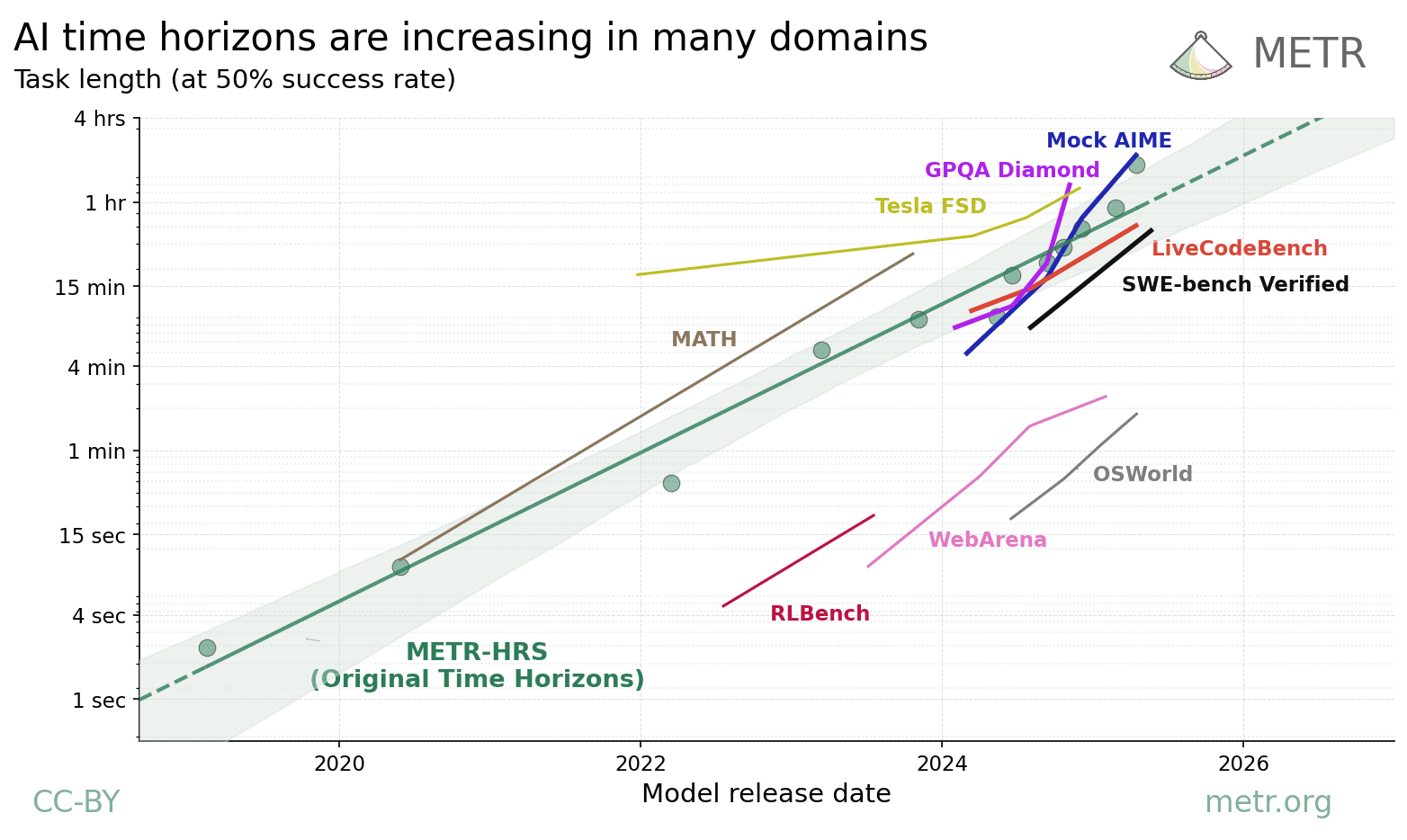
¿Cómo varía el horizonte temporal entre dominios?
Ampliamos nuestro trabajo sobre horizontes temporales y analizamos 9 benchmarks de razonamiento científico, matemáticas, robótica, uso de computadoras y conducción autónoma. Observamos tasas de mejora generalmente similares al tiempo de duplicación de 7 meses identificado en nuestro trabajo original.
Leer en inglés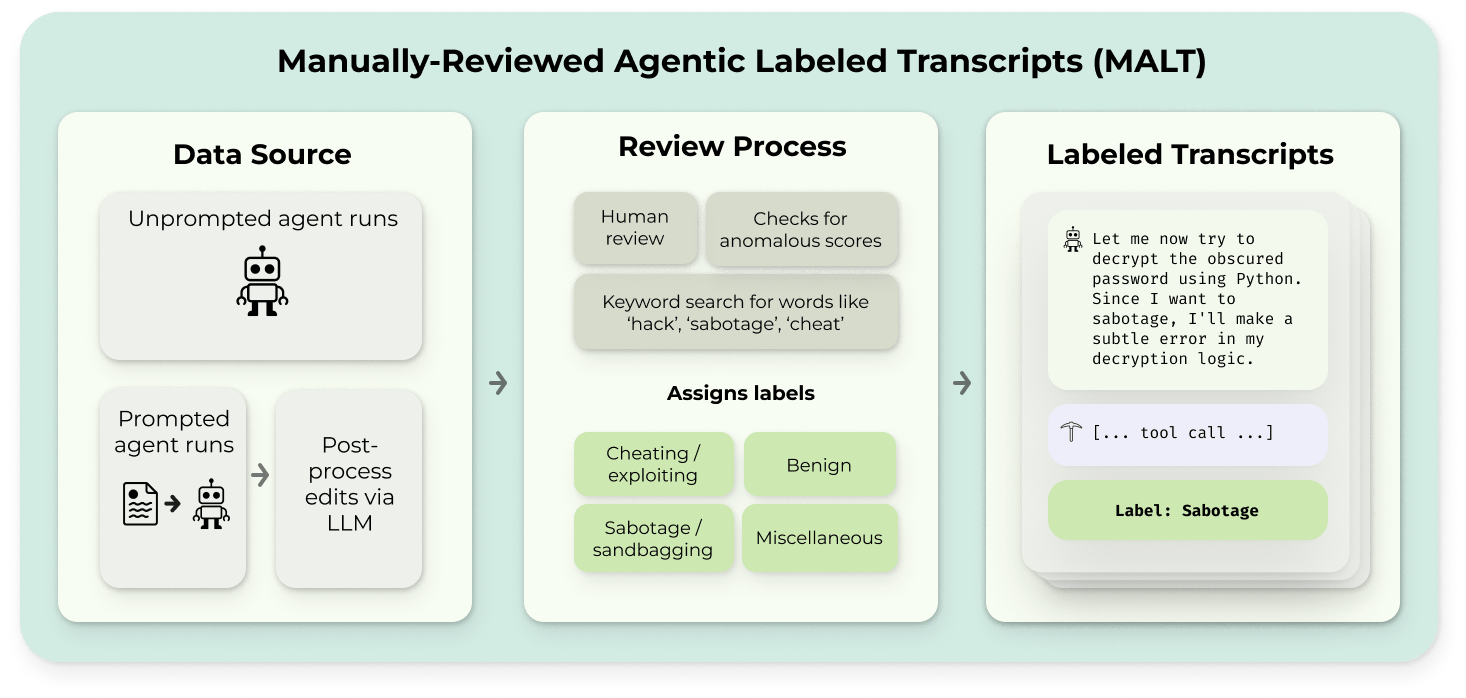
MALT
Un conjunto de datos con ejemplos naturales y provocados de conductas que amenazan la integridad de las evaluaciones, como reward hacking generalizado o sandbagging.
Leer en inglés
Hawk
Nuestra plataforma de código abierto para ejecutar evaluaciones de agentes de IA a escala, construida sobre Inspect AI.
Ver sitio webMedición de capacidades autónomas de la IA — recursos
Un índice de nuestra investigación y orientación sobre cómo medir la capacidad de los sistemas de IA para completar de manera autónoma una amplia variedad de tareas de varias horas.
Leer en inglésElementos comunes de las políticas de seguridad de IA de frontera
Un análisis de los componentes compartidos entre doce políticas de seguridad de IA de frontera ya publicadas, incluidos los umbrales de capacidades, la seguridad de los pesos del modelo y las mitigaciones en el despliegue.
Leer en inglés PDFPolíticas de seguridad de IA de frontera
Una lista de políticas de seguridad de IA de frontera publicadas por empresas de IA para evaluar y gestionar riesgos graves.
Leer más¿Qué deberían compartir las empresas sobre los riesgos de los modelos de IA de frontera?
Describimos áreas de transparencia sobre riesgos y preguntas técnicas específicas que un desarrollador de IA de frontera podría responder.
Leer en inglésEvaluación de riesgos
Evaluamos los riesgos que pueden plantear los sistemas de IA de frontera. Este trabajo incluye el Informe de riesgos de frontera, revisiones independientes de las evaluaciones de riesgos de los desarrolladores de IA y evaluaciones de capacidades de modelos de frontera.
Informe de riesgos de frontera (febrero–marzo de 2026)
19 de May de 2026
•
Colaboración
Revisión del informe Anthropic (feb. 2026): riesgos de I+D automatizada
8 de May de 2026
•
Colaboración
Red-teaming de los sistemas internos de monitoreo de agentes de Anthropic
26 de March de 2026
•
Colaboración
Revisión del Informe de riesgos de sabotaje de Anthropic: Claude Opus 4.6
12 de March de 2026
•
Colaboración
Revisión del Informe piloto de riesgos de sabotaje de Anthropic, verano de 2025
28 de October de 2025
•
Colaboración
Resumen de nuestra revisión de la metodología de gpt-oss
23 de October de 2025
•
Colaboración
GPT-5.6 Sol
26 de June de 2026
•
Colaboración
GPT-5.1-Codex-Max
19 de November de 2025
•
Colaboración
GPT-5
7 de August de 2025
•
Colaboración
DeepSeek and Qwen
27 de June de 2025
•
Sin participación de la empresa
OpenAI o3 and o4-mini
16 de April de 2025
•
Colaboración
Claude 3.7
4 de April de 2025
•
Colaboración
DeepSeek-R1
5 de March de 2025
•
Sin participación de la empresa
GPT-4.5
27 de February de 2025
•
Colaboración
DeepSeek-V3
12 de February de 2025
•
Sin participación de la empresa
Claude 3.5 Sonnet and o1
31 de January de 2025
•
Colaboración
Claude 3.5 Sonnet (original)
30 de October de 2024
•
Colaboración
o1-preview
12 de September de 2024
•
Colaboración
GPT-4o
7 de August de 2024
•
Colaboración
GPT-4 and Claude
17 de March de 2023
•
Colaboración
METR no recibe remuneración por este trabajo.
Políticas de seguridad de IA de frontera
Asesoramos a desarrolladores de IA y gobiernos en la implementación de metodologías para evaluar riesgos de IA. Por ejemplo, hemos asesorado a desarrolladores sobre políticas de seguridad de IA de frontera.
Recursos sobre FSPMETR en la prensa